1.5.Architecture de l’Ordinateur
Plan
du chapitre:
1. Les principaux
constituants
1.1 Dans l’Unité Centrale : l’unité
de traitement
1.2 Dans l’Unité Centrale : l’unité
de commande
1.3 Dans l’Unité Centrale : les
Unités d’échange
1.4 Exemples de machine à une adresse
: un micro-processeur
1.5 Les Bus
1.6 Schéma générald’une
micro-machine fictive
1.7 Notion de jeu d’instructions-machine
1.8 Architectures RISC et CISC
1.9 Pipe line dans un processeur
1.10 Architectures super-scalaire
1.11 Principaux modes d'adressages des instructions machines
2. Mémoires - Mémoire
centrale
2.1 Mémoire
2.2 Les différents
types de mémoires
2.3 Les unités de capacité
2.4 Mémoire centrale : définitions
2.5 Mémoire centrale : caractéristiques
2.6 Mémoire cache (ECC, associative)
3. Une petite machine
pédagogique 8 bits " PM "
3.1 Unité centrale
de PM (pico-machine)
3.2 Mémoire centrale
de PM
3.3 Jeu d’instructions
de PM
4. Mémoire de masse ( externe ou auxiliaire)
4.1 Disques magnétiques - disques durs
4.2 Disques optiques compacts - CD / DVD
 PanneauArchitec.dif\PresArchitec.exe
PanneauArchitec.dif\PresArchitec.exe
1. Les principaux
constituants d'une machine minimale
Un ordinateur, nous l’avons déjà
noté, est composé d’un centre et d’une périphérie.
Nous allons nous intéresser au cœur
d’un ordinateur mono-processeur. Nous savons que celui-ci est composé
de :
-
Une Unité centrale comportant
:
-
Unité de traitement,
-
Unité de contrôle,
-
Unités d’échanges.
Nous décrivons ci-après l'architecture minimale illustrant simplement
le fonctionnement d'un ordinateur (machine de Von Neumann).
1.1 Dans l’Unité
Centrale : l’Unité
de Traitement
Elle est chargée d’effectuer
les traitements des opérations de types arithmétiques ou
booléennes. L’UAL est son principal constituant.
Elle est composée au minimum
:
-
d’un registre de données
RD
-
d’un accumulateur ACC
-
d’une unité arithmétique
et logique : UAL
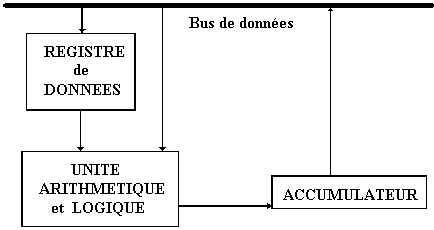
Schéma général théorique de l’unité de traitement :
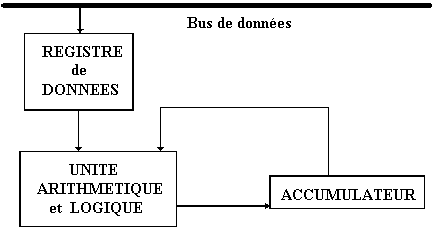
machine à une adresse
|
machine à plusieurs adresses
|
La fonction du registre de données
(mémoire rapide) est de contenir les données transitant entre
l’unité de traitement et l’extérieur.
La fonction de l’accumulateur
est principalement de contenir les opérandes ou les résultats
des opérations de l’UAL.
La fonction de l’UAL est d’effectuer
en binaire les traitements des opérations qui lui sont soumises
et qui sont au minimum:
-
Opérations arithmétiques
binaires: addition,multiplication, soustraction, division.
-
Opérations booléennes
: et, ou, non.
-
Décalages dans un registre.
Le résultat de l’opération est mis dans l’accumulateur (Acc) dans le cas
d'une machine à une adresse, dans des registres internes dans le cas de plusieurs
adresses.
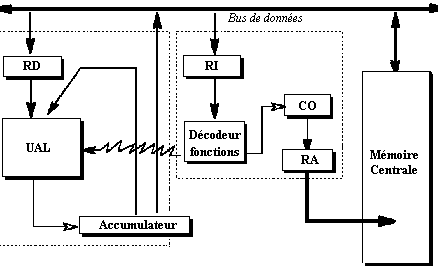
1.2 Dans l’Unité
Centrale : l’Unité
de Contrôle ou de Commande
Elle est chargée de commander
et de gérer tous les différents constituants de l’ordinateur
(contrôler les échanges, gérer l’enchaînement
des différentes instructions, etc...)
Elle est
composée au minimum de :
-
d’un registre instruction RI,
-
d’un compteur ordinal CO,
-
d’un registre adresse RA,
-
d’un décodeur de fonctions,
-
d’une horloge.
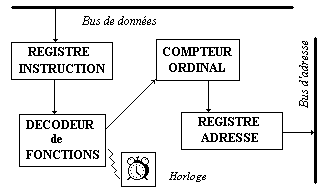
Schéma général
de l’unité de contrôle
Vocabulaire
:
| Bit
= plus petite unité d’information binaire (un objet physique ayant
deux états représente un bit). |
| Processeur
central
= unité de commande + unité de traitement. |
| Instruction
= une ligne de texte comportant un code opération, une ou plusieurs
références aux opérandes. |
Soit l’instruction fictive d’addition
du contenu des deux mémoires x et y dont le résultat est
mis dans z :
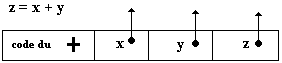 opérateur références opérandes
opérateur références opérandes
| Registre
instruction
= contient l’instruction en cours d’exécution, elle demeure dans
ce registre pendant toute la durée de son exécution. |
| Compteur
ordinal
= contient le moyen de calculer l’adresse de la prochaine instruction à
exécuter. |
| Registre
adresse
= contient l’adresse de la prochaine instruction à exécuter. |
| Décodeur
de fonction
= associé au registre instruction, il analyse l’instruction à
exécuter et entreprend les actions appropriées dans l’UAL
ou dans la mémoire centrale. |
Au début, la différentiation des processeurs s'effectuait en fonction
du nombre d'adresses contenues dans une instruction machine. De nos jours,
un micro-processeur comme le pentium par exemple, possède des instructions
une adresse, à deux adresses, voir à trois adresses dont certaines sont des
registres. En fait deux architectures machines coexistent sur le marché :
l'architecture RISC et l'architecture CISC, sur lesquelles nous reviendrons
plus loin. Historiquement l'architecture CISC est la première, mais les micro-processeur
récents semblent utiliser un mélange de ces deux architectures profitant
ainsi du meilleur de chacune d'elle.
Il existe de très bons ouvrages spécialisés uniquement dans l'architecture
des ordinateurs nous renvoyons le lecteur à certains d'entre eux cités dans
la bibliographie. Dans ce chapitre notre objectif est de fournir au lecteur
le vocabulaire et les concepts de bases qui lui sont nécessaires et utiles
sur le domaine, ainsi que les notions fondamentales qu'il retrouvera dans
les architectures de machines récentes. L'évolution matérielle est actuellement
tellement rapide que les ouvrages spécialisés sont mis à jour en moyenne
tous les deux ans.
-
Une unité d’échange
est spécialisée dans les entrées/sorties.
-
Ce peut être un simple canal,
un circuit ou bien un processeur particulier.
-
Cet organe est placé entre
la mémoire et un certain nombre de périphériques (dans
un micro-ordinateur ce sont des cartes comme la carte son, la carte vidéo,
etc...).
Une unité d’échange
soulage le processeur central dans les tâches de gestion du transfert
de l’information.
Les périphériques
sont très lents par rapport à la vitesse du processeur (rapport
de 1 à 109). Si le processeur central était chargé
de gérer les échanges avec les périphériques
il serait tellement ralenti qu’il passerait le plus clair de son temps
à
attendre.
1.4 Exemple
de machine à une adresse : un micro-processeur
Un micro-processeur a les mêmes
caractéristiques que celles d’un processeur central avec un niveau
de complexité et de sophistication moindre.
C’est essentiellement une machine
à une adresse, c’est à dire une partie code opérande
et une référence à un seul opérande. Ce genre
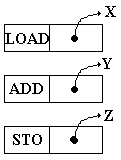
de machine est fondé sur un cycle de passage par l’accumulateur.
L’opération précédente
z = x + y , se décompose dans une telle machine fictivement en 3
opérations distinctes :
LoadAcc x {chargement
de l’accumulateur avec x : (1)}
Add y {préparation
des opérandes x et y vers l’UAL : (2)}
{lancement commande de l’opération
dans l’UAL : (3)}
{résultat transféré
dans l’accumulateur : (3)}
Store z {copie de
l’accumulateur dans z : (4)}
L’accumulateur gardant son
contenu au final
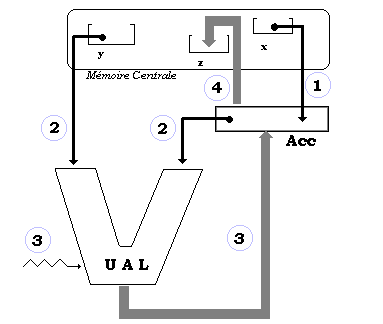
Comparaison de "programme" réalisant le calcul de l'opération précédente
"z = x + y "avec une machine à une adresse et une machine à trois adresses
:
|
Une machine à une adresse
(3 instructions) |
Une machine à trois adresses
(1 instruction) |
|
|
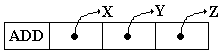
|
1.5 Les Bus
Un bus est un dispositif destiné
à assurer le transfert simultané d’informations entre les
divers composants d’un ordinateur.
On distingue trois catégories
de Bus :
-
Bus d’adresses (unidirectionnel)
-
il permet à l’unité
de commande de transmettre les adresses à rechercher et à
stocker.
-
Bus de données (bi-directionnel)
-
sur lequel circulent les instructions
ou les données à traiter ou déjà traitées
en vue de leur rangement.
-
Bus de contrôle (bi-directionnel)
-
transporte les ordres et les signaux
de synchronisation provenant de l’unité de commande vers les divers
organes de la machine. Il véhicule aussi les divers signaux de réponse
des composants.
Largeur du bus
Pour certains Bus on désigne par largeur du Bus, le nombre
de bits qui peuvent être transportés en même temps par le Bus, on dit aussi
transportés en parallèle.
Les principaux Bus de données récents de micro-ordinateur
Les Bus de données sont essentiellement des bus "synchrones", c'est
à dire qu'ils sont cadencés par une horloge spécifique qui fonctionne à un
fréquence fixée. Entre autres informations commerciales, les constructeurs
de Bus donnent en plus de la fréquence et pour des raison psychologiques,
le débit du Bus qui est en fait la valeur du produit de la fréquence par
la largeur du Bus, ce débit correspond au nombre de bits par seconde transportés
par le Bus.
Quelques chiffres sur des Bus de données parallèles des années 2000 :
|
BUS |
Largeur |
Fréquence |
Débit |
Utilisation |
|
PCI |
64 bits |
66 MHz |
528 Mo/s |
Processeur/périphérique non graphique |
|
AGP |
32 bits |
66 MHz x 8 |
4 Go/s |
Processeur/carte graphique |
|
SCSI |
16 bits |
40 MHz |
80 Mo/s |
Echanges entres périphériques |
Il existe aussi des "Bus série" ( Bus qui transportent les bits les
uns à la suite des autres, contrairement aux Bus parallèles), les deux plus
récents concurrents équipent les matériels de grande consommation : USB et
Firewire.
|
BUS |
Débit |
Nombre de périphériques acceptés |
Ces Bus évitent de connecter des périphériques divers comme
les souris, les lecteurs de DVD, les GSM, les scanners, les imprimantes,
les appareils photo, …, sur des ports spécifiques de la machine
|
|
USB |
1,5 Mo/s |
127 |
|
USB2 |
60 Mo/s |
127 |
|
Firewire |
50 Mo/s |
63 |
|
FirewireB |
200 Mo/s |
63 |
1.7 Notion de jeu d’instructions-machine
: Les premiers programmes
comme défini précédemment,
une instruction-machine est une instruction qui est directement exécutable
par le processeur.
L’ensemble de toutes les instructions-machine
exécutables par le processeur s’appelle le " jeu d’instructions
" de l’ordinateur. Il est composé au minimum de quatre grandes classes
d’instructions dans les micro-processeurs :
-
instructions de traitement
-
instructions de branchement ou de
déroutement
-
instructions d’échanges
-
instructions de comparaisons
D’autres classes peuvent être
ajoutées pour améliorer les performances de la machine (instructions
de gestion mémoire, multimédias etc..)
1.8 Architectures CISC et RISC
Traditionnellement, depuis les années 70 on dénomme processeur à architecture CISC (Complex Instruction Set Code) un processeur dont le jeu d'instructions possède les propriétés suivantes :
- Il contient beaucoup de classes d'instructions différentes.
- Il contient beaucoup de type d'instructions différentes complexes et de taille variable.
- Il se sert de beaucoup de registres spécialisés et de peu de registres généraux.
L'architecture RISC (Reduced Instruction Set Code)
est un concept mis en place par IBM dans les années 70, un processeur RISC
est un processeur dont le jeu d'instructions possède les propriétés suivantes
:
- Le nombre de classes d'instructions différentes est réduit par rapport à un CISC.
- Les instructions sont de taille fixe.
- Il se sert de beaucoup de registres généraux.
- Il fonctionne avec un pipe-line
Depuis les décennies 90, les microprocesseur adoptent le meilleur des
fonctionnalités de chaque architecture provoquant de fait la disparition
progressive de la différence entre RISC et CISC et le inévitables polémiques
sur l'efficacité supposée meilleure de l'une ou de l'autre architecture.
1.9 Pipe-line dans un processeur
Soulignons qu'un processeur est une machine séquentielle ce qui signifie
que le cycle de traitement d'une instruction se déroule séquentiellement.
Supposons que par hypothèse simplificatrice, une instruction machine soit
traitée en 3 phases :
1 - lecture : dans le registre instruction (RI)
2 - décodage : extraction du code opération et des opérandes
3 - exécution : du traitement et stockage éventuel du résultat.
Représentons chacune de ces 3 phases par une unité matérielle
distinctes dans le processeur (on appelle cette unité un "étage") et figurons schématiquement les 3 étages de traitement d'une instruction :
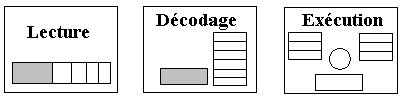
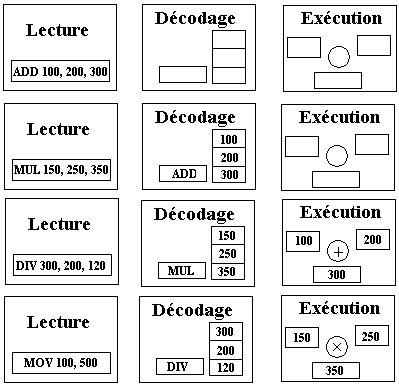
Supposons que suivions pas à pas l'exécution des 4 instructions
machines suivants le long des 3 étages précédents :
ADD 100, 200, 300
MUL 150, 250, 350
DIV 300, 200, 120
MOV 100, 500
Chacune des 4 instruction est traitée séquentiellement en 3 phases
sur chacun des étages; une fois une instruction traitée par le dernier étage
(étage d'exécution) le processeur passe à l'instruction suivante et la traite
au premier étage et ainsi de suite :
|
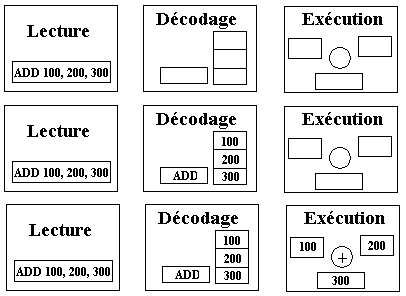
|
Traitement de la première instruction ADD 100, 200, 300
On remarquera que :
- Pendant le temps d'activation d'un étage, les deux autres restent inactifs.
- Il faut attendre la fin du traitement de l'instruction ADD 100, 200,
300 pour pouvoir passer au traitement de l'instruction MUL 150, 250, 350
|
|
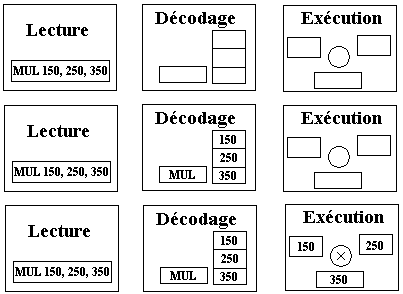
etc … |
Le cycle recommence identique pour l'instruction MUL 150, 250, 350 |
L'architecture pipe-line consiste à optimiser les temps d'attente de
chaque étage, en commençant le traitement de l'instruction suivante dès que
l'étage de lecture a été libéré par l'instruction en cours, et de procéder
identiquement pour chaque étage de telle façon que durant chaque phase, tous
les étages soient occupés à fonctionner (chacun sur une instruction différente).
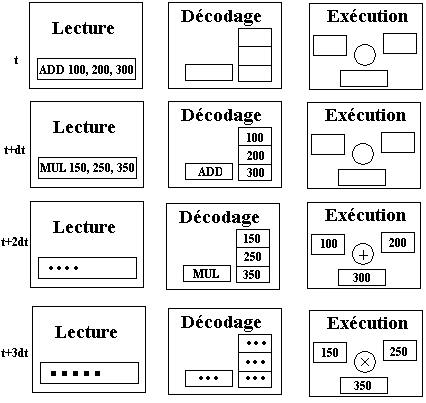
A un instant t0 donné l'étage d'exécution travaille sur les actions à effectuer pour l'instruction de rang n, l'étage de décodage travaille sur le décodage de l'instruction de rang n+1, et l'étage de lecture sur la lecture de l'instruction de rang n+2.
Il est clair que cette technique dénommée architecture pipe-line
accélère le traitement d'une instruction donnée, puisqu'à la fin de chaque
phase une instruction est traitée en entier. Le nombre d'unités différentes
constituant le pipe-line s'appelle le nombre d'étages du pipe-line.
|
La figure ci-dessous illustre le démarrage du traitement des 4 instructions
selon un pipe-line à 3 étages (lecture, décodage, exécution) :
|
etc… |
Période initiale (une seule fois au démarrage)
Chaque étage se met en route
Exécution de l'instruction ADD
Exécution de l'instruction MUL
La prochaine phase verra la fin de l'exécution de l'instruction DIV,…
|
1.10 Architecture super-scalaire
On dit qu'un processeur est super-scalaire lorsqu'il possède plusieurs
pipe-lines indépendants dans lesquels plusieurs instructions peuvent être
traitées simultanément. Dans ce type d'architecture apparaît la notion de
parallélisme avec ses contraintes de dépendances (par exemple lorsqu'une
instruction nécessite le résultat de la précédente pour s'exécuter, ou encore
lorsque deux instructions accèdent à la même ressource mémoire,…).
Examinons l'exécution de notre exemple à 4 instructions sur un processeur
super-scalaire à 2 pipe-lines. Nous supposons nous trouver dans le cas idéal
pour lequel il n'y a aucune dépendance entre deux instructions, nous figurons
séparément le schéma temporel d'exécution de chacun des deux pipe-lines aux
t, t+dt, t+2dt et t+3dt afin d'observer leur comportement et en sachant que
les deux fonctionnent en même temps à un instant quelconque.
Le processeur envoie les deux premières instruction ADD et MUL au pipe-line
n°1, et les deux suivantes DIV et MOV au pipe-line n°2 puis les étages des
deux pipe-lines se mettent à fonctionner.
PIPE-LINE n°1
PIPE-LINE n°2
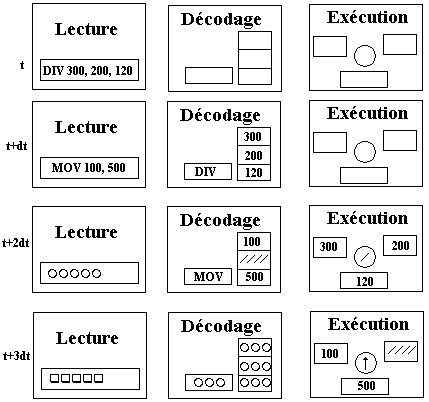
nous remarquerons qu'après de t+dt, chaque phase voit s'exécuter 2 instructions :
à t+2dt ce sont ADD et DIV
à t+3dt se sont MUL et MOV
Rappelons au lecteur que nous avons supposé par simplification de l'explication
que ces 4 instructions sont indépendantes et donc leur ordre d'exécution
est indifférent. Ce n'est dans la réalité pas le cas car par exemple si l'instruction
DIV 300, 200, 120 utilise le contenu de la mémoire 300 pour le diviser par
le contenu de la mémoire 200, et que l'instruction ADD 100, 200, 300 range
dans cette mémoire 300 le résultat de l'addition des contenus des mémoires
100 et 200, alors l'exécution de DIV dépend de l'exécution de ADD. Dans cette
éventualité à t+2dt, le calcul de DIV par le second pipe-line doit "attendre"
que le calcul de ADD soit terminé pour pouvoir s'exécuter sous peine d'obtenir
une erreur en laissant le parallélisme fonctionner : un processeur super-scalaire
doit être capable de désactiver le parallélisme dans une telle condition.
Par contre dans notre exemple, à t+3dt le parallélisme des deux pipe-lines
reste efficace MUL et MOV sont donc exécutées en même temps.
- Le pentium IV de la société Intel intègre un pipe-line
à 20 étages et constitue un exemple de processeur combinant un mélange d'architecture
RISC et CISC. Il possède en externe un jeu d'instruction complexes (CISC),
mais dans son cœur il fonctionne avec des micro-instructions de type RISC
traitées par un pipe-line super-scalaire.
- L'AMD 64 Opteron qui est un des micro-processeur
de l'offre 64 bits du deuxième constructeur mondial de micro-processeur derrière
la société Intel, dispose de 3 pipe-lines d'exécution identiques pour les
calculs en entiers et de 3 pipe-lines spécialisés pour les calculs en virgules
flottante. L'AMD 64 Opteron est aussi un mélange d'architecture RISC-CISC
avec un cœur de micro-instructions RISC comme le pentium IV.
Nous figurons ci-dessous les 3 pipe-lines d'exécution (sur les entiers par exemple) :
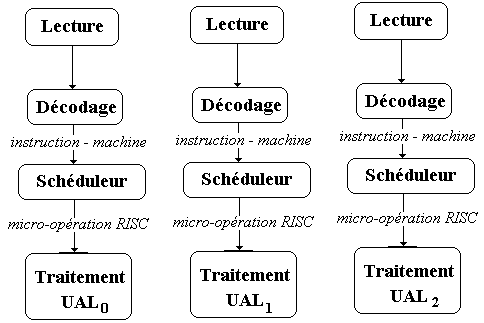
Chacune des 3 UAL effectue les fonctions classiques d'une UAL, plus
des opérations de multiplexage, de drapeau, des fonctions conditionnelles
et de résolution de branchement. Les multiplications sont traitées dans une
unité à part de type pipe-line et sont dirigées vers les pipe-lines UAL0
et UAL1.
1.11 Principaux modes d'adressage des instructions machines
Nous avons indiqué précédemment qu'une instruction machine contenait
des adresses d'opérandes situées en mémoire centrale. En outre, il a été
indiqué que les processeurs centraux disposaient de registres internes. Les
informaticiens ont mis au point des techniques d'adressages différentes en
vue d'accéder à un contenu mémoire. Nous détaillons dans ce paragraphe les
principales d'entre ces techniques d'adressage. Afin de conserver un point
de vue pratique, nous montrons le fonctionnement de chaque mode d'adressage
à l'aide de schémas représentant le cas d'une instruction LOAD de chargement
d'un registre nommé ACC d'une machine à une adresse, selon 6 modes d'adressages
différents.
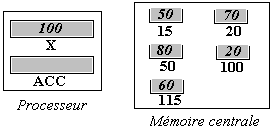
Environnement d'exécution d'un LOAD
Soit à considérer un processeur contenant en particulier deux
registres X chargé de la valeur entière 100 et ACC (accumulateur de machine
à une adresse) et une mémoire centrale dans laquelle nous exhibons 5 mots
mémoire d'adresses 15, 20, 50, 100, 115. Chaque mot et contient un entier
respectivement dans l'ordre 50, 70, 80, 20, 60, comme figuré ci-dessous :
L'instruction "LOAD Oper" a pour fonction de charger le contenu du
registre ACC avec un opérande Oper qui peut prendre 6 formes, chacune de
ces formes représente un mode d'adressage particulier que nous définissons
maintenant.
Adressage immédiat
L'opérande Oper est considéré comme une valeur à charger immédiatement
(dans le registre ACC ici). Par exemple, nous noterons LOAD #15, pour indiquer
un adressage immédiat (c'est à dire un chargement de la valeur 15 dans le
registre ACC).
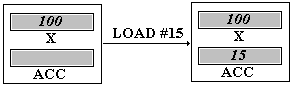
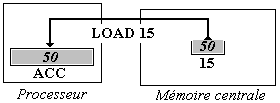
Adressage direct
L'opérande Oper est considéré comme une adresse en mémoire
centrale. Par exemple, nous noterons LOAD 15, pour indiquer un adressage
direct (c'est à dire un chargement du contenu 50 du mot mémoire d'adresse
15 dans le registre ACC).
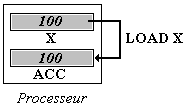
Adressage direct avec registre
L'opérande Oper est un registre interne du processeur (noté
X dans l'exemple), un tel mode d'adressage indique de charger dans ACC le
contenu du registre Oper. Par exemple, nous noterons LOAD X, pour indiquer
un adressage direct avec registre qui charge l'accumulateur ACC avec la valeur
100 contenue dans X.
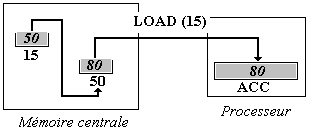
Adressage indirect
L'opérande Oper est considéré comme l'adresse d'un mot1 en mémoire centrale, mais ce mot1 contient lui-même l'adresse d'un autre mot2
dont on doit charger le contenu dans ACC. Par exemple, nous noterons LOAD
(15), pour indiquer un adressage indirect (c'est à dire un chargement dans
le registre ACC, du contenu 80 du mot2 mémoire dont l'adresse 50 est contenue dans le mot1 d'adresse 15).
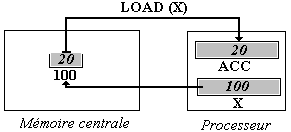
Adressage indirect avec registre
L'opérande Oper est considéré comme un registre dont le contenu
est l'adresse du mot dont on doit charger la valeur dans ACC. Par exemple,
nous noterons LOAD (X), pour indiquer un adressage indirect avec le registre
X (c'est à dire un chargement dans le registre ACC, du contenu 20 du mot
mémoire dont l'adresse 100 est contenue dans le registre X).
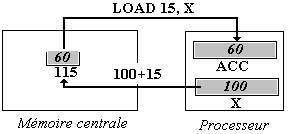
Adressage indexé
L'opérande Oper est un couple formé par un registre R et une adresse adr. La connaissance de l'adresse du mot dont on doit charger la valeur est obtenue par addition de l'adresse adr au contenu du registre R.
Par exemple, nous noterons LOAD 15, X , pour indiquer un adressage indexé
par le registre X (c'est à dire un chargement dans le registre ACC, du contenu
60 du mot mémoire dont l'adresse 115 est obtenue par addition de 15 et du
contenu 100 du registre X).
Quelques remarques sur les différents modes d'adressages (avec l'exemple du LOAD) :
- Le mode direct correspond à des préoccupations de chargement de valeur à des emplacements fixés.
- Les modes indirects permettent à partir d'un emplacement mémoire quelconque
d'atteindre un autre emplacement mémoire et donc autorise des traitements
sur les adresses elles-mêmes.
- Le mode indexé est très utile lorsque l'on veut atteindre une famille
de cellules mémoires contiguës possédant une adresse de base (comme pour
un tableau). L'instruction LOAD 15,X permet si l'on fait varier le contenu
du registre X de la valeur 0 à la valeur 10 (dans une itération par exemple)
d'atteindre les mots d'adresse 15, 16, … , 25.
Les registres sont très présents dans les micro-processeurs du marché
- Le processeur AMD 64 bits Optéron travaille avec 16 registres
généraux de 64 bits et 16 registres généraux
de 128 bits.
- Le processeur pentium IV travaille avec 8 registres généraux
32 bits et 8 registres généraux 80 bits.
- L'architecture IA 64 d'Intel et HP est fondée sur des instructions
machines très longues travaillant avec 128 registres généraux 64 bits et
128 registres généraux 82 bits pour les calculs classiques.
|
Il en est des processeurs comme il en est des moteurs à explosion dans
les voitures, quelle que soit leur sophistication technique (processeur vectoriel,
machine parallèle, machine multi-processeur, …)leurs fondements restent établis
sur les principes d'une machine de Von Neumann ( mémoire, registre, adresse,
transfert).
2. Mémoires : mémoire
centrale, mémoire cache
2.1 Mémoire
| Mémoire
:c’est un organe (électronique de nos jours), capable de contenir,
de conserver et de restituer sans les modifier de grandes quantités
d’information. |
2.2 Les différents
types de mémoires
La mémoire vive RAM
(Random Access Memory)
-
Mémoire dans laquelle on
peut lire et écrire.
-
Mémoire volatile (perd
son contenu dès la coupure du courant).
La mémoire morte
ROM (Read Only Memory)
-
Mémoire dans laquelle on
ne
peut que lire.
-
Mémoire permanente
(conserve indéfiniment son contenu).
Les PROM (Programable
ROM)
-
Ce sont des mémoires vierges
programmables une seule fois avec un outil spécialisé s’appelant
un programmateur de PROM.
-
Une fois programmées elles
se comportent dans l’ordinateur comme des ROM.
Les EPROM (Erasable PROM)
-
Ce sont des PROM effaçables
(généralement sous rayonnement U.V),
-
elles sont reprogrammables avec
un outil spécialisé,
-
elles se comportent comme des ROM
en utilisation courante.
- Les EEPROM (Electrical EPROM) sont effaçables par signaux électriques.
- Les FLASH EEPROM sont des EEPROM effaçables par bloc.
2.3 Les unités de
capacité
Les unités de mesure
de stockage de l’information sont :
| Le
bit (pas de notation) |
| L’octet = 23
bits = 8 bits. (noté 1 o) |
| Le Kilo-octet =
210 octets =1024 o (noté 1 Ko) |
| Le Méga-octet
= 220 octets =(1024)2 o (noté 1 Mo) |
| Le Giga-octet =
230 octets =(1024)3 o (noté 1 Go) |
| Le Téra-octet
= 240 octets =(1024)4 o (noté 1 To)… |
Les autres sur-unités sont
encore peu employées actuellement.
2.4 Mémoire centrale
: définitions
| Mot
: c’est un regroupement de n bits constituant une case mémoire
dans la mémoire centrale. Ils sont tous numérotés. |
| Adresse
: c’est le numéro d’un mot-mémoire (case mémoire)
dans la mémoire centrale. |
| Programme
: c’est un ensemble d’instructions préalablement codées
(en binaire) et enregistrées dans la mémoire centrale sous
la forme d’une liste séquentielle d’instructions. Cette liste
représente une suite d’actions élémentaires que l’ordinateur
doit accomplir sur des données en entrée, afin d’atteindre
le résultat recherché. |
| Organisation
: La mémoire centrale est organisée en bits et en mots. Chaque
mot-mémoire est repéré bijectivement par son adresse
en mémoire centrale. |
Contenu
: La mémoire centrale contient sous forme binaire, deux sortes d’informations
-
des programmes,
-
des données.
|
| Composition
: Il doit être possible de lire et d’écrire dans une mémoire
centrale. Elle est donc habituellement composée de mémoires
de type RAM. |
Remarques
-
Un ordinateur doté d’un programme
est un automatisme apte seulement à répéter le même
travail(celui dicté par le programme).
-
Si l’on change le programme en mémoire
centrale, on obtient un nouvel automatisme.
|
2.5 Mémoire centrale
: caractéristiques
La mémoire centrale peut
être réalisée grâce à des technologies
différentes. Elle possède toujours des caractéristiques
générales qui permettent de comparer ces technologies. En
voici quelques unes :
| La capacité représente
le nombre maximal de mots que la mémoire peut stocker simultanément. |
| Le temps d’accès est
le temps qui s’écoule entre le stockage de l’adresse du mot à
sélectionner et l’obtention de la donnée. |
| Le temps de cycle ou cycle mémoire
est égal au temps d’accès éventuellement additionné
du temps de rafraîchissement ou de réécriture pour
les mémoires qui nécessitent ces opérations. |
| La volatilité, la permanence. |
Terminons ce survol des possibilités
d’une mémoire centrale, indiquons que le mécanisme d’accès
à une mémoire centrale par le processeur est essentiellement
séquentiel et se décrit selon trois phases :
-
stockage,
-
sélection,
-
transfert.
Pour l'instant :
| Un ordinateur est une machine
séquentielle de Von Neumann dans laquelle s’exécutent ces
3 phases d’une manière immuable, que ce soit pour les programmes
ou pour les données. |
La mémoire centrale est un élément d'importance dans l'ordinateur, nous
avons vu qu'elle est composée de RAM en particulier de RAM dynamiques nommées
DRAM dont on rappelle que sont des mémoires construite avec un transistor
et un condensateur. Depuis l'année 2004 les micro-ordinateurs du commerce sont tous
équipés de DRAM, le sigle employé sur les notices techniques est DDR qui
est l'abréviation du sigle DDR SDRAM dont nous donnons l'explication :
Ne pas confondre SRAM et SDRAM
- Une SRAM est une mémoire statique (SRAM = Statique RAM)
construite avec des bascules.
- Une SDRAM est une mémoire dynamique DRAM qui
fonctionne à la vitesse du bus mémoire, elle est donc synchrone avec le fonctionnement
du processeur le "S" indique la synchronicité (SDRAM = Synchrone DRAM).
Une DDR SDRAM
C'est une SDRAM à double taux de transfert pouvant expédier et
recevoir des données deux fois par cycle d'horloge au lieu d'une seule fois.
Le sigle DDR signifie Double Data Rate.
Les performances des mémoires s'améliorent régulièrement,
le secteur d'activité est très innovant, le lecteur retiendra que les mémoires
les plus rapides sont les plus chères et que pour les comparer en ce domaine,
il faut utiliser un indicateur qui se nomme le cycle mémoire.
Temps de cycle d'une mémoire ou cycle mémoire : le processeur attend
Nous venons de voir qu'il représente l'intervalle de temps qui
s'écoule entre deux accès consécutif à la mémoire toutes opération cumulées.
Un processeur est cadencé par une horloge dont la fréquence est donnée actuellement
en MHz (Méga Hertz). Un processeur fonctionne beaucoup plus rapidement que
le temps de cycle d'une mémoire, par exemple prenons un micro-processeur
cadencé à 5 MHz auquel est connectée une mémoire SDRAM de temps de cycle
de 5 ns (ordre de grandeur de matériels récents). Dans ces conditions le
processeur peut accéder aux données selon un cycle qui lui est propre 1/5MHz
soit un temps de 2.10-1 ns, la mémoire SDRAM ayant un temps de cycle de 5 ns, le processeur doit attendre 5ns / 2.10-1 ns = 25 cycles propres
entre deux accès aux données de la mémoire. Ce petit calcul montre au lecteur
l'intérêt de l'innovation en rapidité pour les mémoires.
C'est aussi pourquoi on essaie de ne connecter directement au
processeur que des mémoires qui fonctionnent à une fréquence proche de celle
du processeur.
Les registres d'un processeur sont ses mémoires les plus rapides
Un processeur central est équipé de nombreux registres servant
à différentes fonctions, ce sont en général des mémoires qui travaillent
à une fréquence proche de celle du processeur , actuellement leur architecture
ne leur permet pas de stocker de grandes quantités d'informations. Nous avons
vu au chapitre consacré aux circuits logiques les principaux types de registres
(registres parallèles, registres à décalages, registres de comptage, …)
Nous avons remarqué en outre que la mémoire centrale qui stocke
de très grandes quantités d'informations (relativement aux registres) fonctionne
à une vitesse plus lente que celle du processeur. Nous retrouvons alors la
situation classique d'équilibre entre le débit de robinets qui remplissent
ou vident un réservoir. En informatique, il a été prévu de mettre entre le
processeur et la mémoire centrale une sorte de réservoir de mémoire intermédiaire
nommée la mémoire cache.
2.6 Mémoire cache
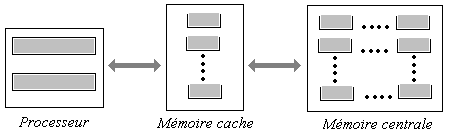
La mémoire cache (on dit aussi le cache) est une variété de mémoire
plus rapide que la mémoire centrale (un peu moins rapide que les registres).
La particularité technique actuelle de la mémoire cache est que plus sa taille
est grande plus son débit a tendance à ralentir.
La caractéristique fonctionnelle du cache est de servir à stocker
des instructions et des données provenant de la mémoire centrale et qui ont
déjà été utilisées les plus récemment par le processeur central. |
Actuellement le cache des micro-processeurs récents du marché
est composé de deux niveaux de mémoires de type SRAM la plus rapide (type
de mémoire RAM statique semblable à celle des registres) : le cache de niveau
un est noté L1, le cache de niveau deux est noté L2.
Le principe est le suivant :
Le cache L1 est formé de deux blocs séparés, l'un
servant au stockage des données, l'autre servant au stockage des instructions.
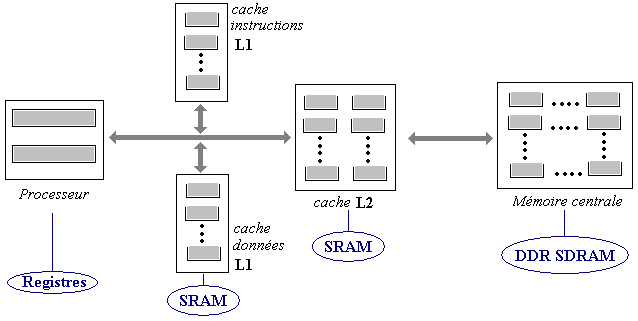
- Si un étage du processeur cherche une donnée, elle va être d'abord
recherchée dans le cache de donnée L1 et rapatriée dans un registre adéquat,
si la donnée n'est pas présente dans le cache L1, elle sera recherchée dans
le cache L2.
- Si la donnée est présente dans L2, elle est alors rapatriée dans un registre adéquat et recopiée
dans le bloc de donnée du cache L1. Il en va de même lorsque
la donnée n'est pas présente dans le cache L2, elle est alors
rapatriée depuis la mémoire centrale dans le registre adéquat et recopiée dans le cache L2.
Généralement la mémoire cache de niveau L1 et celle
de niveau L2 sont regroupées dans la même puce que le processeur
(cache interne).
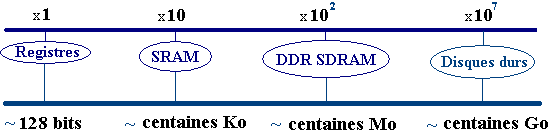
Nous figurons ci-dessous le facteur d'échelle relatif entre les
différents composants mémoires du processeur et de la mémoire centrale (il
s'agit d'un coefficient de multiplication des temps d'accès à une information
selon la nature de la mémoire qui la contient). Les registres, mémoires les
plus rapides se voient affecter la valeur de référence 1 :

L'accès par le processeur à une information située dans la DDR
SDRAM de la mémoire centrale est 100 fois plus lente qu'un accès à une information
contenue dans un registre.
Par exemple, le processeur AMD 64 bits Optéron travaille avec un
cache interne L1 de 64 Ko constitué de mémoires associatives (type ECC pour
le bloc L1 de données et type parité pour le bloc L1 d'instructions), le
cache L2 de l'Optéron a une taille de 1 Mo constitué de mémoires 64 bits
associatives de type ECC, enfin le contrôleur de mémoire accepte de la DDR
SDRAM 128 bits jusqu'à 200 Mhz en qualité ECC.
Définition de mémoire ECC (mémoire à code correcteur d'erreur)
Une mémoire ECC est une mémoire contenant des bits supplémentaires
servant à détecter et à corriger une éventuelle erreur ou altération de l'information
qu'elle contient (par exemple lors d'un transfert).
La technique la plus simple est celle du bit de parité (Parity
check code), selon cette technique l'information est codée sur n bits et
la mémoire contient un n+1 ème bit qui indique si le nombre de bits codant
l'information contenue dans les n bits est pair (bit=0)ou impair(bit=1).
C'est un code détecteur d'erreur.
Exemple d'une mémoire à 4 bits plus bit de parité (le bit de poids faible contient la parité) :
Information 10010 à
bit de parité = 0 , car il y a deux bits égaux à 1 (nombre pair)
Information 11110 à
bit de parité = 0 , car il y a quatre bits égaux à 1 (nombre pair)
Information 11011 à
bit de parité = 1 , car il y a trois bits égaux à 1 (nombre impair)
Une altération de deux bits (ou d'un nombre pair de bits) ne modifiant
pas la parité du décompte ne sera donc pas décelée par ce code :
Supposons que l'information 10010 soit altérée en 01100
( le bit de parité ne change pas car le nombre de 1 de l'information altérée
est toujours pair, il y en a toujours 2 ! ). Ce code est simple peu coûteux,
il est en fait un cas particulier simple de codage linéaire systématique
inventés par les spécialistes du domaine.
Mémoire ECC générale
Les mathématiciens mis à contribution à travers la théorie des
groupes et des espaces vectoriels fournissent des modèles de codes détecteur
et correcteur d'erreurs appelés codes linéaire cycliques, les codes de Hamming
sont les plus utilisés. Pour un tel code permettant de corriger d'éventuelles
erreur de transmission, il faut ajouter aux n
bits de l'information utile, un certain nombre de bits supplémentaires
représentant un polynôme servant à corriger les n bits utiles.
Pour une mémoire ECC de 64 bits utiles, 7 supplémentaires sont
nécessaires pour le polynôme de correction, pour une mémoire de 128 bits
utiles, 8 bits sont nécessaires. Vous remarquez que l'Optéron d'AMD utilise
de la mémoire ECC pour le cache L1 de données et de la mémoire à parité pour
le cache instruction. En effet, si un code d'instruction est altéré, l'étage
de décodage du processeur fera la vérification en bloquant l'instruction
inexistante, la protection apportée par la parité est suffisante; en revanche
si c'est une donnée qui est altérée dans le cache L1 de données, le polynôme
de correction aidera alors à restaurer l'information initiale.
Mémoire associative
C'est un genre de mémoire construit de telle façon que la recherche
d'une information s'effectue non pas à travers une adresse de cellule, la
mémoire renvoyant alors le contenu de la cellule, mais plutôt en donnant
un "contenu" à rechercher dans la mémoire et celle-ci renvoie l'adresse de la cellule.
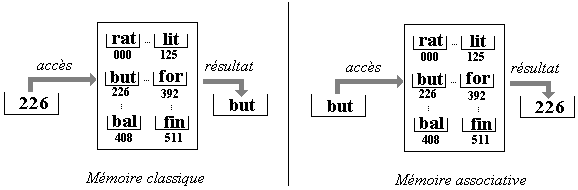
Une mémoire cache est une mémoire associative, ainsi elle permet
d'adresser directement dans la mémoire centrale qui n'est pas associative.
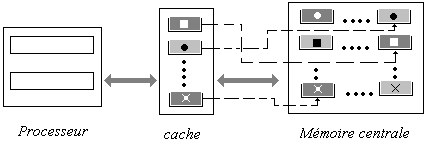
On peut considérer une mémoire cache comme une sorte de table
de recherche contenant des morceaux de la mémoire centrale. La mémoire centrale
est divisée en blocs de n
mots, et la mémoire cache contient quelques un de ces blocs qui ont
été chargés précédemment.
Notation graphiques utilisées :
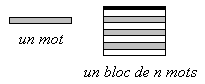
Mécanisme synthétique de lecture-écriture avec cache :
Le processeur fournit l'adresse d'un mot à lire :
1°) Si ce mot est présent dans le cache, il se trouve dans un
bloc déjà copié à partir de son original dans le MC (mémoire centrale), il
est alors envoyé au processeur :
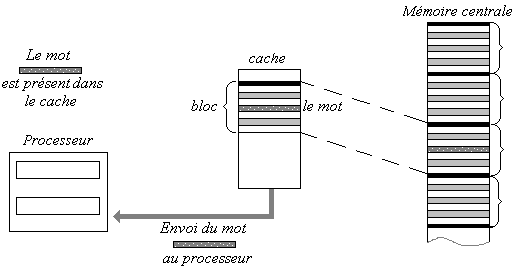
|
2°) Si ce mot n'est pas présent dans le cache, l'adresse porte alors sur
un mot situé dans un bloc présent dans la MC (mémoire centrale). |
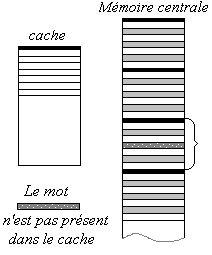
|
Dans cette éventualité le bloc de la MC dans lequel se trouve
le mot, se trouve recopié dans le cache et en même temps le mot est envoyé
au processeur :
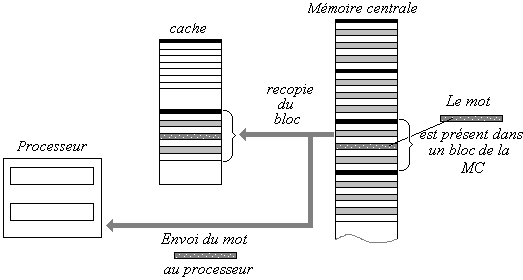
Pour l'écriture l'opération est semblable, selon que le mot est déjà dans le cache ou non.
Lorsque le mot est présent dans le cache et qu'il est modifié
par une écriture il est modifié dans le bloc du cache et modifié aussi dans
la MC :
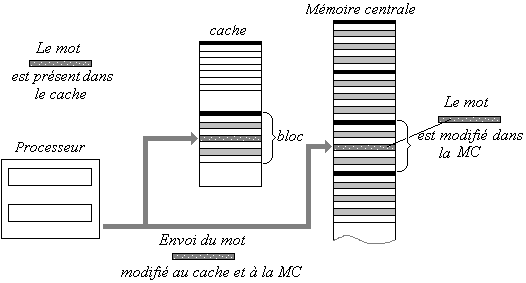
Ce fonctionnement montre qu'il est donc nécessaire que la mémoire
cache soit liée par une correspondance entre un mot situé dans elle-même
et sa place dans la MC. Le fait que la mémoire cache soit constituée de
mémoires associatives, permet à la mémoire cache lorsqu'un mot est sélectionné
de fournir l'adresse MC de ce mot et donc de pouvoir le modifier.
3. Une petite machine pédagogique
8 bits " PM "
PanneauArchitec.dif\Picodelf.dif
3.1 Unité centrale
de PM (pico-machine)
| Objectif:
Support
pédagogique destiné à faire comprendre l'analyse et
le cheminement des informations dans un processeur central d'ordinateur
fictif.
|
-
La mémoire centrale est à
mots de 8 bits, les adresses sont sur 16 bits.
-
le processeur est doté d'instructions
immédiates ou relatives.
-
Les instructions sont de 3 types
à 1,2 ou 3 octets.
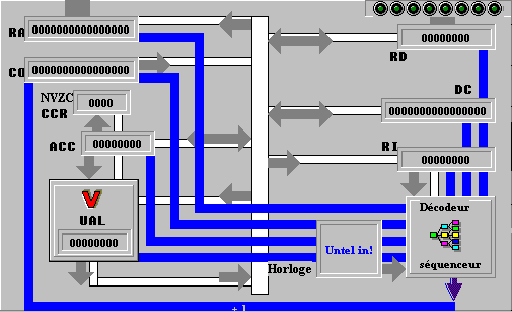
Description générale
de l’unité centrale de PM :
RA
= Registre Adresse sur 16 bits
CO
= Compteur Ordinal sur 16 bits
DC
= Registre de formation d'adresse sur 16 bits
RD
= Registre de Données sur 8 bits
UAL
= Unité Arithmétique et Logique effectuant les calculs sur
8 bits avec possibilité de débordement.
Acc
= Accumulateur sur 8 bits (machine à une adresse).
RI
= Registre Instruction sur 8 bits (instruction en cours d'exécution).
Décodeur
de fonction.
séquenceur
Horloge
CCR
= un Registre de 4 Codes Condition N, V, Z, C,
BUS
de contrôle (bi-directionnel)
BUS
interne (circulation des informations internes).
L'unité centrale de PM
est simulée sur le tableau de bord ci-dessous :
vers le bus d’adressevers
le bus de données
3.2 Mémoire centrale
de PM
La mémoire centrale de
PM est de 512 octets, ce qui permet dans une machine 8 bits de voir comment
est construite la technique d'adressage court (8 bits) et d'adressage long
(16 bits).
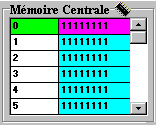
|adresse|contenu|
Elle est connectée à
l’unité centrale à travers deux bus : un bus d’adresse et
un bus de données.
3.3 Jeu d’instructions de
PM
PM est doté du jeu
d'instructions suivant :
| addition
avec l'accumulateur |
| ADD #<valeur> 2 octets code=16 |
| ADD <adr 16 bits> 3 octets code=18 |
| ADD <adr 8 bits> 2 octets
code=17 |
| chargement
de l'accumulateur |
| LDA #<valeur> 2 octets code=10 |
| LDA <adr 16 bits> 3 octets code=12 |
| LDA <adr 8 bits> 2 octets
code=11 |
| rangement
de l'accumulateur |
|
| STA <adr 16 bits> 3 octets code=15 |
| STA <adr 8 bits> 2 octets
code=14 |
| positionnement
indicateurs CNVZ |
STC (C=1) 1 octet code=100
STN (N=1) 1 octet code=101
STV (V=1) 1 octet code=102
STZ (Z=1) 1 octet code=103
CLC (C=0) 1 octet code=104
CLN (N=0) 1 octet code=105
CLV (V=0) 1 octet code=106
CLZ (Z=0) 1 octet code=107 |
| branchement
relatif sur indicateur |
BCZ (brancht.si C=0) 2 octets code=22
BNZ (brancht.si N=0) 2 octets code=23
BVZ (brancht.si V=0) 2 octets code=24
BZZ (brancht.si Z=0) 2 octets code=25
END (fin programme) 1 octet code=255 |
Dans le CCR les 4 bits
indicateurs sont dans cet ordre : N V Z C.
Ils peuvent être
:
-
soit positionnés
automatiquement par la machine:
N = le bit de poids
fort de l'Accumulateur
V = 1 si overflow (dépassement
capacité) 0 sinon
Z = 1 si Accumulateur
vaut 0
Z = 0 si Accumulateur
<>0
C = 1 si retenue (dans
l'addition) sinon 0
-
soit positionnés
par programme.
| Exemple de programme en PM |
LDA #18 ; {chargement de l’accumulateur
avec la valeur 18}
STA 50 ; {rangement de l’accumulateur dans la mémoire
n°50}
LDA #5 ; {chargement de l’accumulateur avec la
valeur 5}
STA 51 ; {rangement de l’accumulateur dans la mémoire
n°51}
ADD 50 ; {addition de l’accumulateur avec la mémoire
n°50}
STA 52 ; {rangement de l’accumulateur dans la mémoire
n°52}
END |
Le lecteur est encouragé à utiliser le logiciel d'assistance
Pico-machine du package pédagogique qui se trouve accessible à travers l'onglet
simulateur et met en œuvre :
4. Mémoire de masse ( externe ou auxiliaire)
Les données peuvent être stockées à des fin de conservation
,ailleurs que dans la mémoire centrale volatile par construction avec les
constituants électroniques actuels. Des périphériques spécialisés sont utilisés
pour ce genre de stockage longue conservation, en outre ces mêmes périphériques
peuvent stocker une quantité d'information très grande par rapport à la capacité
de stockage de la mémoire centrale.
On dénomme dispositifs de stockage de masse, de tels périphériques.
Les mémoires associées à ces dispositifs se dénomment mémoires
de masse, mémoires externes ou encore mémoires auxiliaires, par abus de langage
la mémoire désigne souvent le dispositif de stockage.
Les principaux représentant de cette famille de mémoires sont :
- Les bandes magnétiques (utilisés dans de très faible cas)
- Les disques magnétiques : les disquettes (en voie d'abandon), les disques durs (les plus utilisés).
- Les CD (très utilisés mais bientôt supplantés par les DVD)
- Les DVD
Des technologies ont vu le jour puis se sont éteintes (tambour
magnétique, cartes magnétiques, mémoires à bulles
magnétiques,…)
A part les bandes magnétiques qui sont un support ancien encore
utilisé à fonctionnement séquentiel, les autres supports (disques, CD, DVD)
sont des mémoires qui fonctionnent à accès direct.
4.1 Disques magnétiques - disques durs
Nous décrivons l'architecture
générale des disques magnétiques encore appelés disques durs (terminologie
américaine hard disk, par opposition aux disquettes nommées floppy disk)
très largement employés dans tous les types d'ordinateur comme mémoire auxiliaire.
Un micro-ordinateur du commerce dispose systématiquement d'un
ou plusieurs disques durs et au minimum d'un lecteur-graveur combiné de CD-DVD
permettant ainsi l'accès aux informations extérieures distribuées sur les
supports à faibles coût comme les CD et les DVD qui les remplacent progressivement.
Un disque dur est composé d'un disque métallique sur lequel
est déposé un film magnétisable, sur une seule face ou sur ses deux faces
:
Ce film magnétique est composé de grains d'oxyde magnétisable
et c'est le fait que certaines zones du film conservent ou non un champ magnétique,
qui représente la présence d'un bit à 0 ou bien à 1.
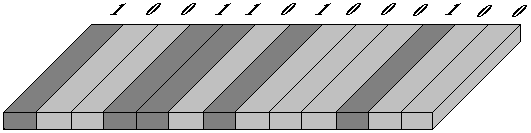
Coupe d'une tranche de disque et figuration de zones magnétisées interprétées comme un bit
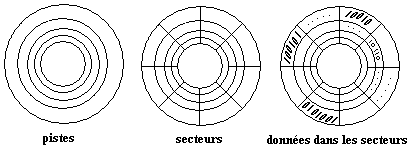
Organisation générale d'un disque dur
Un disque dur est au minimum composé de pistes numérotées
et de secteurs numérotés, les données sont stockées
dans les secteurs.
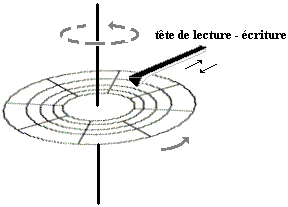
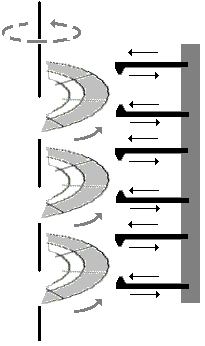
Le disque tourne sur son axe à vitesse d'environ 7200 tr/mn et un secteur donné peut être atteint par un dispositif mobile appelé tête de lecture-écriture,
soit en lecture (analyse des zones magnétiques du secteur) ou en écriture
(modification du champ des zones magnétiques du secteur). Opération semblable
à celle qui se passe dans un magnétoscope avec une bande magnétique qui passe
devant la tête de lecture. Dans un magnétoscope à une tête, seule la bande
magnétisée défile, la tête reste immobile, dans un disque dur le disque tourne
sur son axe de symétrie et la tête est animée d'un mouvement de translation
permettant d'atteindre n'importe qu'elle piste du disque.
|
|
La tête "flotte" sur un coussin d'air engendré par la rotation très rapide
du disque, ce qui la maintient à une hauteur constante de la surface du disque
adéquate pour l'enregistrement du champ magnétique du film. |
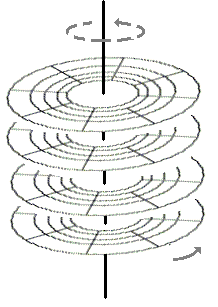
Afin d'augmenter la capacité d'un "disque dur" on empile plusieurs
disques physique sur le même axe et on le muni d'un dispositif à plusieurs
têtes de lecture-écriture permettant d'accéder à toutes les faces et toutes
les pistes de tous les disques physiques. La pile de disques construite est encore appelée un disque dur.
|
Pile de disques |

têtes |
disques et têtes en action |
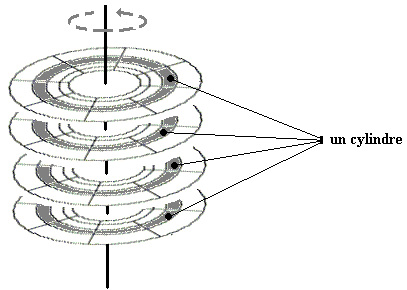
Dans une pile de disques on ajoute la notion de cylindre qui
repère toutes les pistes portant le même numéro sur chaque face de chacun
des disques de la pile.
Formatage
Avant toute utilisation ou bien
de temps à autre pour tout effacer, les disques durs doivent être "formatés",
opération qui consiste à créer des pistes magnétiques et des secteurs vierges
( tous les bits à 0 par exemple). Depuis 2005 les micro-ordinateurs sont
livrés avec des disques durs dont la capacité de stockage dépasse les 200
Go, ces disques sont pourvu d'un système de mémoire cache (semblable à celui
décrit pour la cache du processeur central) afin d'accélérer les transferts
de données. Le temps d'accès à une information sur un disque dur est de l'ordre
de la milliseconde.
4.2 Disques optique compact ou CD (compact disk)
Untel disque peut être en lecture
seule (dans ce cas on parle de CD-ROM) ou bien en lecture et écriture (dans
ce cas on parle de CD réinscriptible). Il est organisé à peu près comme un
disque magnétique, avec une différence notable : il n'a qu'une seule piste
qui se déroule sous la forme d'une spirale.
Si sur un disque magnétique les bits codant l'information
sont représentés par des grains magnétisables, dans un CD ce sont des creux
provoqués par brûlure d'un substrat aluminisé réfléchissant qui représentent
les bits d'information.
Gravure d'un CD-ROM
Comme pour un disque dur, le formatage
appelé gravure du CD crée les secteurs et les données en même temps. Plus
précisément c'est l'absence ou la présence de brûlures qui représente un
bit à 0 ou à 1, le substrat aluminisé est protégé par une couche de plastique
transparent.

Après gravure avec le graveur de CD, les bits sont matérialisés :

Principe de lecture d'un CD :
Lorsque le substrat est lisse (non
brûlé) à un endroit matérialisant un bit, le rayon lumineux de la diode laser
du lecteur est réfléchi au maximum de son intensité vers la cellule de réception.
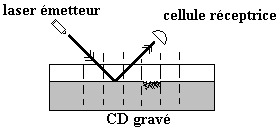
On dira par exemple que le bit examiné vaut 0 lorsque l'intensité du signal réfléchi est maximale.
Lorsque le substrat est brûlé à un endroit matérialisant un
bit, la partie brûlée est irrégulière et le rayon lumineux de la diode laser
du lecteur est mal réfléchi vers le capteur (une partie du rayonnement est
réfléchi par les aspérités de la brûlure dans plusieurs directions). Dans
cette éventualité l'intensité du signal capté par réflexion est moindre.
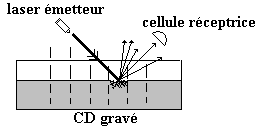
On dira par exemple que le bit examiné
vaut 1 lorsque l'intensité du signal réfléchi n'est
pas maximale.
La vitesse du disque est variable contrairement à un disque
dur qui tourne à vitesse angulaire fixe. En effet la lecture de la piste
en spirale nécessite une augmentation au fur et à mesure de l'éloignement
du centre. Le temps d'accès à une information sur un CD 54x est de l'ordre
de 77 millisecondes.
Le temps d'accès sur un CD ou un DVD est 10 fois plus lent
que celui d'un disque dur et environ 100 fois moins volumineux qu'un disque
dur.
Toutefois leur coût très faible et leur facilité de transport
font que ces supports sont très utilisé de nos jours et remplacent la disquette
moins rapide et de moindre capacité.
Nous pouvons reprendre l'échelle comparative des temps d'accès
des différents types de mémoires en y ajoutant les mémoires de masse et en
indiquant en dessous l'ordre de grandeur de leur capacité :