Plan du chapitre:
1.1 Les principaux types d’ OS
2. Processus et multi-threading dans un OS
2.1 Les processus agissent grâce au système
2.2 Le multi-threading
2.3 Relation entre threads et processus
2.4 L'ordonnancement pour gérer le temps du processeur
2.5 Un algorithme classique non préemptif (cas batch processing)
2.6 Deux algorithmes classiques préemptifs (cas interactif)
3. Gestion de la mémoire par un OS de multi-programmation
3.1 Mémoire virtuelle et segmentation
3.2 Mémoire virtuelle et pagination
4. Les OS des mico-ordinateurs
4.1 Le système d'exploitation du monde libre : Linux
4.2 Le système d'exploitation Windows de Microsoft
1.
Notion de système d’exploitation
Un ordinateur est constitué de matériel (hardware) et de logiciel (software). Cet ensemble est à la disposition de un ou plusieurs utilisateurs. Il est donc nécessaire que quelque chose dans l’ordinateur permette la communication entre l’homme et la machine. Cette entité doit assurer une grande souplesse dans l’interface et doit permettre d’accéder à toutes les fonctionnalités de la machine. Cette entité douée d’une certaine intelligence de communication se dénomme " la machine virtuelle ". Elle est la réunion du matériel et du système d’exploitation (que nous noterons OS par la suite pour Operationg System).
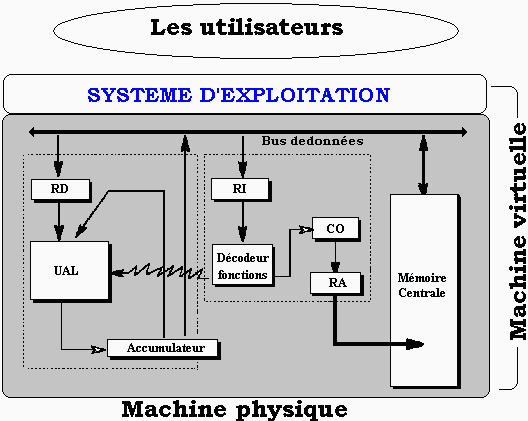
Le système d’exploitation d’un ordinateur est chargé d’assurer les fonctionnalités de communication et d’interface avec l’utilisateur. Un OS est un logiciel dont le grand domaines d’intervention est la gestion de toutes les ressources de l’ordinateur :Un système d’exploitation n’est pas un logiciel unique mais plutôt une famille de logiciels. Une partie de ces logiciels réside en mémoire centrale (nommée résident ou superviseur), le reste est stocké en mémoire de masse (disques durs par exemple).
- mémoires,
- fichiers,
- périphériques,
- entrée-sortie,
- interruptions, synchronisation...
Afin d’assurer une bonne liaison entre les divers logiciels de cette famille, la cohérence de l’OS est généralement organisée à travers des tables d’interfaces architecturées en couches de programmation (niveaux abstraits de liaison). La principale tâche du superviseur est de gérer le contrôle des échanges d’informations entre les diverses couches de l’OS.
1.1 Les principaux types d’ OS
Nous avons vu dans le tableau
synoptique des différentes générations d’ordinateurs
que les OS ont subi une évolution parallèle à celle
des architectures matérielles. Nous observons en première
approximation qu’il existe trois types d’OS différents, si l’on
ignore les systèmes rudimentaires de la 1ère génération.
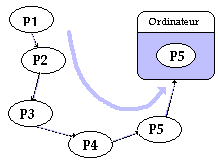
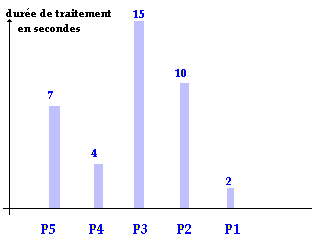
L’axe des abscisses indiquant l’ordre de passage précédent (P5, puis P4 etc...) nous voyons que les temps d’attente d’un utilisateur ne dépendent pratiquement pas de la durée d’exécution de son programme mais surtout de l’ordre du passage (les derniers sont pénalisés surtout si en plus leur temps propre d’exécution est faible comme P1 par exemple).
Une vision abstraite et synthétique d’un tel système est de considérer que 5 tables suffisent à le décrire. La table :
Relativement aux temps d’attente, un système de monoprogrammation est injuste vis à vis des petits programmes.
La 3ème génération d’ordinateur a vu naître avec elle les OS de multiprogrammation. Dans un tel système, plusieurs utilisateurs peuvent être présents en " même temps " dans la machine et se partagent les ressources de la machine pendant tout leur temps d’exécution.
En reprenant le même exemple que précédemment, P1, P2, P3, P4, P5 sont exécutés cycliquement par l’OS qui leur alloue les ressources nécessaires (disque, mémoire, fichier,...) pendant leur tranche de temps d’exécution.
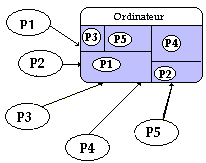
En reprenant un diagramme des temps d’exécution semblable au précédent on obtient :
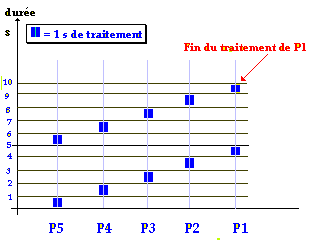
Nous avons ici exposé
uniquement des exécutions ne nécessitant jamais d’interruptions,
ni de priorité, en supposant que le temps fictif alloué pour
l’exécution est de 1 seconde.
Le système exécute P5 pendant 1 seconde, puis abandonne P5 et exécute P4 pendant 1 seconde, puis abandonne P4..., lorsqu’il a fini le temps alloué à P1, il recommence à parcourir cycliquement la liste (P5, P4, P3, P2, P1)et réalloue 1 seconde de temps d’exécution à P5 etc... jusqu'à ce qu’un programme ait terminé son exécution et qu’il soit sorti de la table des programmes à exécuter.
Une vision abstraite déduite du paragraphe précédent et donc simplificatrice, est de décrire un tel système comme composé des 5 types de tables précédentes en y rajoutant de nouvelles tables et en y incluant la notion de priorité d’exécution hiérarchisée. Les programmes se voient affectés une priorité qui permettra à l’OS selon les niveaux de priorité, de traiter certains programmes plus complètement ou plus souvent que d’autres.
Relativement aux temps d’attente,
un système de multiprogrammation rétablit une certaine justice
entre petits et gros programmes.
La 4ème génération
d’ordinateur a vu naître les réseaux d’ordinateurs connectés
entre eux et donc de nouvelles fonctionnalités, comme l’interfaçage
réseau, qui ont enrichi les OS déjà existants. De
nouveaux OS entièrement orientés réseaux sont construits
de nos jours.
1.2 Systèmes d'exploitation actuels
De nos jours, les systèmes d'exploitation sont des systèmes de multi-programmation dirigés vers certains type d'applications, nous citons les trois types d'application les plus significatifs.
Système inter-actif
Un tel système a vocation à permettre à l'utilisateur d'intervenir pratiquement à toutes les étapes du fonctionnement du système et pendant l'exécution de son programme (Windows Xp, Linux sont de tels systèmes).
Système temps réel
Comme son nom l'indique, un système de temps réel exécute et synchronise des applications en tenant compte du temps, par exemple un système gérant une chaîne de montage de pièces à assembler doit tenir compte des délais de présentation d'une pièce à la machine d'assemblage, puis à celle de soudage etc…
Système embarqué
C'est un système d'exploitation dédié à des applications en nombre restreint et identifiées : par exemple un système de gestion et de contrôle des mesures à l'intérieur d'une sonde autonome, un système pour assistant personnel de poche, système pour téléphone portables se connectant à internet etc…
Les principales caractéristiques d'un système d'exploitation de multi-programmation sont fondées sur la gestion des processus et la gestion de la mémoire à allouer à ces processus.
2. Processus et multi-threading dans un OS
Contexte d'exécution d'un programmeLorsqu'un programme qui a été traduit en instructions machines s'exécute, le processeur central lui fournit toutes ses ressources (registres internes, place en mémoire centrale, données, code,…), nous nommerons cet ensemble de ressources mises à disposition d'un programme son contexte d'exécution.
Programme et processus
Nous appelons en première analyse, processus l'image en mémoire centrale d'un programme s'exécutant avec son contexte d'exécution. Le processus est donc une abstraction synthétique d'un programme en cours d'exécution et d'une partie de l'état du processeur et de la mémoire.
Lorsque l'on fait exécuter plusieurs programmes "en même temps", nous savons qu'en fait la simultanéité n'est pas réelle. Le processeur passe cycliquement une partie de son temps (quelques millisecondes) à exécuter séquentiellement une tranche d'instructions de chacun des programmes selon une logique qui lui est propre, donnant ainsi l'illusion que tous les programmes sont traités en même temps parce que la durée de l'exécution d'une tranche d'instruction est plus rapide que notre attention consciente.
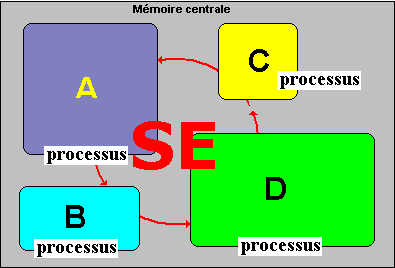
Le SE (système d'exploitation) gère 4 processus
2.1 Les processus agissent grâce au système
Processus
Nous donnons la définition précise de processus proposée par A.Tannenbaum, spécialiste des systèmes d'exploitation : c'est un programme qui s'exécute et qui possède son propre espace mémoire, ses registres, ses piles, ses variables et son propre processeur virtuel (simulé en multi-programmation par la commutation entre processus effectuée par le processeur unique).Un processus a donc une vie propre et une existence éphémère, contrairement au programme qui lui est physiquement présent sur le disque dur. Durant sa vie, un processus peut agir de différentes manières possibles, il peut se trouver dans différents états, enfin il peut travailler avec d'autres processus présent en même temps que lui.
Différentes actions possibles d'un processus
- Un processus est créé.
- Un processus est détruit.
- Un processus s'exécute (il a le contrôle du processeur central et exécute les actions du programme dont il est l'image en mémoire centrale).
- Un processus est bloqué (il est en attente d'une information).
- Un processus est passif (il n'a plus le contrôle du processeur central).
On distingue trois actions particulières appelées états du processus
- Etat actif : le processus contrôle le processeur central et s'exécute).
- Etat passif
: le processus est temporairement suspendu et mis en attente, le processeur central travaille alors avec un autre processus.- Etat bloqué
: le processus est suspendu toutefois le processeur central ne peut pas le réactiver tant que l'information attendue par le processus ne lui est pas parvenue.Que peut faire un processus ?
- Il peut créer d'autre processus
- Il travaille et communique avec d'autres processus (notion de synchronisation et de messages entre processus)
- Il peut posséder une ressource à titre exclusif ou bien la partager avec d'autre processus.
C'est le rôle de l'OS que d'assurer la gestion complète de la création, de la destruction, des transitions d'états d'un processus. C'est toujours à l'OS d'allouer un espace mémoire utile au travail de chaque processus. C'est encore l'OS qui assure la synchronisation et la messagerie inter-processus.
Le système d'exploitation implémente cette gestion des processus à travers une table des processus qui contient une entrée par processus créé par le système sous forme d'un bloc de contrôle du processus (PCB ou Process Control Block). Le PCB contient lui-même toutes les informations de contexte du processus, plus des informations sur l'état du processus.
Lorsque la politique de gestion de l'OS prévoit que le processus Pk est réactivable (c'est au tour de Pk de s'exécuter), l'OS va consulter le PCB de Pk dans la table des processus et restaure ou non l'activation de Pk selon son état (par exemple si Pk est bloqué, le système ne l'active pas).
Afin de séparer les tâches d'un processus, il a été mis en place la notion de processus léger (ou thread).
Nous pouvons voir le multithreading comme un changement de facteur d'échelle dans le fonctionnement de la multi-programmation.
- En fait, chaque processus peut lui-même fonctionner comme le système d'exploitation en lançant des sous-tâches internes au processus et par là même reproduire le fonctionnement de la multi-programmation. Ces sous-tâches sont nommées "flux d'exécution" "processus légers"ou Threads.
- Qu'est exactement un thread
- Un processus travaille et gère, pendant le quantum de temps qui lui est alloué, des ressources et exécute des actions sur et avec ces ressources. Un thread constitue la partie exécution d'un processus alliée à un minimum de variables qui sont propres au thread.
- Un processus peut comporter plusieurs threads.
- Les threads situés dans un même processus partagent les mêmes variables générales de données et les autres ressources allouées au processus englobant.
- Un thread possède en propre un contexte d'exécution (registres du processeur, code, données)
- Cette répartition du travail entre thread et processus, permet de charger le processus de la gestion des ressources (fichiers, périphériques, variables globales, mémoire,…) et de dédier le thread à l'exécution du code proprement dit sur le processeur central (à travers ses registres, sa pile lifo etc…).
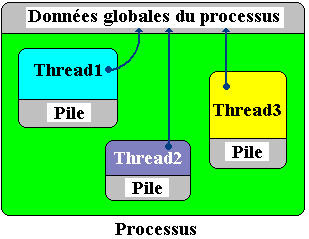
- Le processus applique au niveau local une multi-programmation interne qui est nommée le multithreading. La différence fondamentale entre la multi-programmation et nommée le multithreading se situe dans l'indépendance qui existe entre les processus,alors que les threads sont liés à minima par le fait qu'ils partagent les même données globales (celles du processus qui les contient).
2.3 Relations entre thread et processus
- Ci-dessous nous supposons que le processus D assigné à l'application D, exécute en même temps les 3 Threads D1, D2 et D3 :
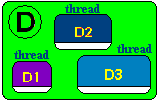
- Soit par exemple 4 processus qui s'exécutent "en même temps" dont le processus D précédent possédant 3 threads :
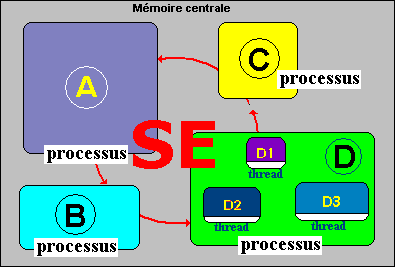
- La commutation entre les threads d'un processus fonctionne identiquement à la commutation entre les processus.
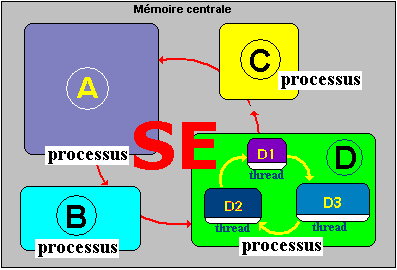
- Chaque thread se voit alloué cycliquement, lorsque le processus D est exécuté une petite tranche de temps dans le quantum de temps alloué au processus. Le partage et la répartition du temps sont effectués uniquement par le système d'exploitation.
- Dans l'exemple ci-dessous, nous figurons les processus A, B, C et le processus D avec ses threads dans un graphique représentant un quantum de temps d'exécution alloué par le système et supposé être la même pour chaque processus.
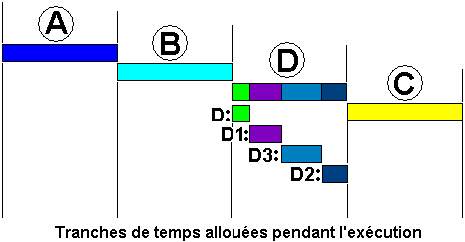
- Le système ayant alloué le même temps d'exécution à chaque processus, lorsque par exemple le tour vient au processus D de s'exécuter dans son quantum de temps, il exécutera pendant une petite sous-tranche de temps D1, puis D2, enfin D3 et attendra le prochain cycle.
Voici sous les mêmes hypothèses de quantum de temps égal d'exécution alloué à chaque processus A, B, C et D, le comportement de l'exécution sur 2 cycles consécutifs :
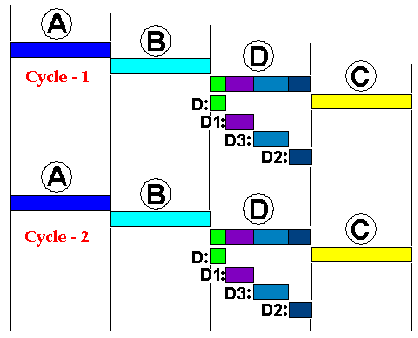
- La majorité des systèmes d'exploitation (Windows, Unix, MacOs,...) supportent le Multithreading.
- Différences et similitudes entre threads et processus :
- La communication entre les threads est plus rapide que la communication entre les processus.
- Les Threads possèdent les mêmes états que les processus.
- Deux processus peuvent travailler sur une même donnée (un tableau par exemple) en lecture et en écriture, dans une situation de concurrence dans laquelle le résultat final de l'exécution dépend de l'ordre dans lequel les lectures et écritures ont lieu, il en est de même pour les threads.
Les langages de programmation récents comme C++, Delphi, Java et C# disposent chacun de classes permettant d'écrire et d'utiliser des threads.
Concurrence en cas de données partagées
Un OS met en place les notions de sections critiques, de verrou, de sémaphore et de mutex afin de gérer les situations de concurrence des processus et des threads dans le cadre de données partagées.
Mais il existe aussi une autre situation de concurrence inéluctable sur une machine mono-processeur, lorsqu'il s'agit de partager le temps d'activité du processeur central entre plusieurs processus. Une solution à cette concurrence est de gérer au mieux la répartition du quantum de temps alloué aux processus.
2.4 L'ordonnancement pour gérer le temps du processeur
- Dans un système d'exploitation, c'est l'ordonnanceur (scheduler ou logiciel d'ordonnancement) qui établit la liste des processus prêts à être exécutés et qui effectue le choix du processus à exécuter immédiatement selon un algorithme d'ordonnancement. Dans ce paragraphe le mot tâche désigne aussi bien un processus qu'un thread.
Ordonnancement coopératif ou préemptif
- Un algorithme d'ordonnancement est dit préemptif lorsqu'une tâche qui s'exécute peut être interrompue après un délai d'horloge fixé appelé quantum de temps, même si la tâche est en cours d'exécution.
- Un algorithme d'ordonnancement est dit coopératif lorsqu'une tâche s'exécute soit jusqu'au terme de son exécution, soit parce qu'elle libère de son propre chef l'activité du processeur
Remarque
Dans les deux cas préemptif et coopératif, la tâche peut suspendre elle-même son exécution si elle reconnaît que le temps d'attente d'une donnée risque d'être trop long comme dans le cas d'une entrée-sortie vers un périphérique ou encore l'attente d'un résultat communiqué par une autre tâche. La différence importante entre ces deux modes est le fait qu'une tâche peut être suspendue après un délai maximum d'occupation du processeur central
Dans un OS interactif comme Windows, Linux, Mac OS par exemple, la préemption est fondamentale car il y a beaucoup d'intervention de l'utilisateur pendant l'exécution des tâches. Une des premières versions de Windows (Windows 3) était coopérative et lorsqu'une tâche buggait elle pouvait bloquer tout le système (par exemple le lecteur de CD-ROM ouvert en cours d'exécution en attente d'une lecture impliquait un gel du système), ce n'est plus le cas depuis les versions suivantes de Windows (98, Xp, …)
2.5 Un algorithme classique non préemptif dans un OS de batch processing :
FCFS (First Come First Served)
- Dans un OS de traitement par lot (batch processing) qui est un système dans lequel les utilisateurs n'interagissent pas avec l'exécution du programme (mise à jour et gestion des comptes clients dans une banque, calculs scientiques,…), multi-programmation avec préemption n'est pas nécessaire, la coopération seule suffit et les performances de calcul en sont améliorées.
Un algorithme d'ordonnancement important et simple purement coopératif de ce type d'OS se nomme First Come First Served (premier arrivé, premier servi). Toutes les tâches éligibles (prêtes à être exécutées) sont placées dans une file d'attente unique, la première tâche T1 en tête de file est exécutée :
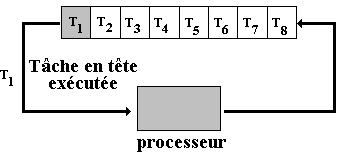
jusqu'à ce qu'elle s'interrompe elle-même (entrée-sortie, résultat,…) elle est alors remise en queue de liste et c'est la tâche suivante T2 de la liste qui est exécutée et ainsi de suite :
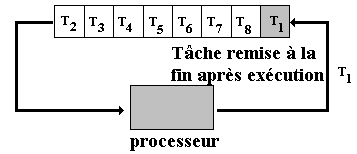
2.6 Deux algorithmes classiques préemptifs dans un OS interactif
- Dans un OS interactif comme Windows par exemple, ce sont les threads qui sont ordonnancés puisque ce sont les threads qui sont chargés dans un processus, de l'exécution de certaines actions du processus qui sert alors de conteneur aux threads et aux ressources à utiliser. Comme précédemment nous nommons tâche (soit un thread, soit un processus) l'entité à ordonnancer par le système.
Algorithme de plus haute priorité
Les tâches Ti se voient attribuer un ordre de priorité Pk et sont rangées par ordre de priorité décroissant dans une liste de tâches toutes prêtes à être exécutées. Cette liste est organisée comme une file d'attente, il y a une file d'attente par niveau de priorité, dans la file de priorité Pk toutes les tâches Tik ont le même ordre de priorité Pk:
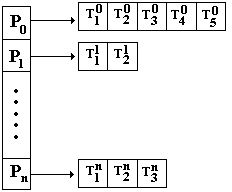
Dans l'exemple ci-contre P0 représente la priorité la plus haute et Pn la priorité la plus basse.
Une tâche est exécutée pendant au plus la durée du quantum de temps qui lui est alloué (elle peut s'interrompre avant la fin de ce quantum de temps).
Les tâches de plus haute priorité sont exécutées d'abord depuis celles de priorité P0 jusqu'à la priorité Pn.
Les tâches Tik de même priorité Pk sont exécutées selon un mécanisme de tourniquet, les unes à la suite des autres jusqu'à épuisement de la file, dès qu'une tâche a fini d'être exécutée, elle est remise en fin de liste d'attente de sa file de priorité :
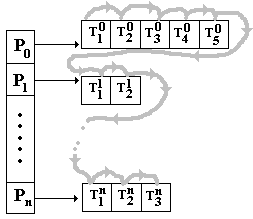
Chemin d'exécution des tâches
etc …
Exécution des tâches de la file de priorité P0
( une fois exécutée, une tâche est rangée à la fin de la file )
Le système peut changer les priorités d'une tâche après l'exécution du quantum de temps qui lui a été alloué.
Algorithme du tourniquet (Round Robin)
C'est le premier algorithme qui a été utilisé en multi-programmation. Il ressemble à l'algorithme FCFS utilisé dans le cas d'un OS de batch processing, le système alloue un quantum de temps identique à chaque tâche ou selon le cas une tranche de temps variable selon le type de tâche.
Toutes les tâches éligibles sont placés dans une file d'attente unique, la première tâche T1 en tête de file est exécutée, jusqu'à ce que :
- Soit elle s'interrompe elle-même (entrée-sortie, résultat,…)
- Soit le quantum de temps qui lui était alloué a expiré.
Dans ce cas, elle est remise en fin de file d'attente et c'est la tâche suivante T2 de la file qui est exécutée selon les mêmes conditions et ainsi de suite :
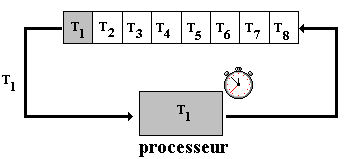
3. Gestion de la mémoire par un OS de multi-programmation
Puisque dans un tel OS, plusieurs tâches sont présentes en mémoire centrale, à un instant donné, il faut donc que chacune dispose d'un espace mémoire qui lui est propre et qui soit protégé de toute interaction avec une autre tâche. Il est donc nécessaire de partitionner la mémoire centrale MC en plusieurs sous-ensembles indépendants.
Plusieurs tâches s'exécutant en mémoire centrale utilisent généralement plus d'espace mémoire que n'en contient physiquement la mémoire centrale MC, il est alors indispensable de mettre en place un mécanisme qui allouera le maximum d'espace mémoire physique utile à une tâche et qui libérera cet espace dès que la tâche sera suspendue. Le même mécanisme doit permettre de stocker, gérer et réallouer à une autre tâche l'espace ainsi libéré.
Les techniques de segmentation et de pagination mémoire dans le cadre d'une gestion de mémoire nommée mémoire virtuelle, sont une réponse à ces préoccupations d'allocation et de désallocation de mémoire physique dans la MC.
Du fait de la multi-programmation, les tâches sont chargées (stockées) dans des parties de la MC dont l'emplacement physique n'est déterminé qu'au moment de leur exécution. Sans entrer très profondément dans les deux mécanismes qui réalisent la répartition de la mémoire allouée aux tâches, la segmentation et la pagination mémoire, nous décrivons d'une manière générale ces deux méthodes ; les ouvrages spécialisés en la matière cités en bibliographie détaillent exhaustivement ces procédés.
3.1 Mémoire virtuelle et segmentation
- On désigne par mémoire virtuelle, une méthode de gestion de la mémoire physique permettant de faire exécuter une tâche dans un espace mémoire plus grand que celui de la mémoire centrale MC.
Par exemple dans Windows et dans Linux, un processus fixé se voit alloué un espace mémoire de 4 Go, si la mémoire centrale physique possède une taille de 512 Mo, le mécanisme de mémoire virtuelle permet de ne mettre à un instant donné dans les 512 Mo de la MC, que les éléments strictement nécessaires à l'exécution du processus, les autres éléments restant stockés sur le disque dur, prêts à être ramenés en MC à la demande.
Un moyen employé pour gérer la topographie de cette mémoire virtuelle se nomme la segmentation, nous figurons ci-après une carte mémoire segmentée d'un processus.
Segment de mémoire
- Un segment de mémoire est un ensemble de cellules mémoires contiguës.
- Le nombre de cellules d'un segment est appelé la taille du segment, ce nombre n'est pas nécessairement le même pour chaque segment, toutefois tout segment ne doit pas dépasser une taille maximale fixée.
- La première cellule d'un segment a pour adresse 0, la dernière cellule d'un segment adrk est bornée par la taille maximale autorisée pour un segment.
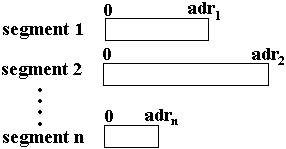
- Un segment contient généralement des informations de même type (du code, une pile, une liste, une table, ...) sa taille peut varier au cours de l'exécution (dans la limite de la taille maximale), par exemple une liste de données contenues dans un segment peut augmenter ou diminuer au cours de l'exécution.
- Les cellules d'un segment ne sont pas toutes nécessairement entièrement utilisées.
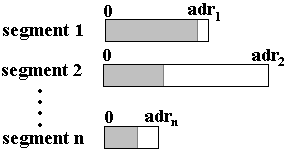
- L'adresse d'une cellule à l'intérieur d'un segment s'appelle l'adresse relative (au segment) ou déplacement. On utilise plus habituellement la notion d'adresse logique permettant d'accéder à une donnée dans un segment, par opposition à l'adresse physique qui représente une adresse effective en mémoire centrale.
C'est un ensemble de plusieurs segments que le système de gestion de la mémoire utilise pour allouer de la place mémoire aux divers processus qu'il gère.
Chaque processus est segmenté en un nombre de segments qui dépend du processus lui-même.
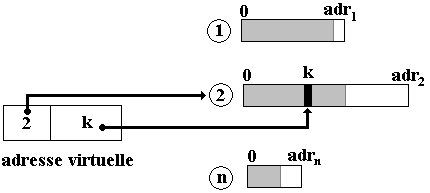
Adresse logique ou virtuelle
Une adresse logique aussi nommée adresse virtuelle comporte deux parties : le numéro du segment auquel elle se réfère et l'adresse relative de la cellule mémoire à l'intérieur du segment lui-même.
Remarques :
- Le nombre de segments présents en MC n'est pas fixe.
- La taille effective d'un segment peut varier pendant l'exécution
- Pendant l'exécution de plusieurs processus, la MC est divisée en deux catégories de blocs : les blocs de mémoire libre (libéré par la suppression d'un segment devenu inutile) et les blocs de mémoire occupée (par les segments actifs).
Fragmentation mémoireLe partitionnement de la MC entre blocs libres et blocs alloués se dénomme la fragmentation mémoire, au bout d'un certain temps, la mémoire contient une multitude de blocs libres qui deviendront statistiquement de plus en plus petits jusqu'à ce que le système ne puisse plus allouer assez de mémoire contiguë à un processus.
Exemple
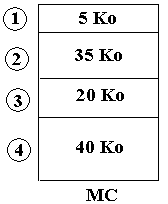
Soit une MC fictive de 100 Ko segmentable en segments de taille maximale 40 Ko, soit un processus P segmenté par le système en 6 segments dont nous donnons la taille dans le tableau suivant :
Numéro du segment
Taille du segment
1
5 Ko
2
35 Ko
3
20 Ko
4
40 Ko
5
15 Ko
6
23 Ko
Supposons qu'au départ, les segments 1 à 4 sont chargés dans la MC :
Supposons que le segment n°2 devenu inutile soit désalloué :
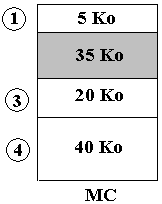
Puis chargeons en MC le segment n°5 de taille 15 Ko dans l'espace libre qui passe de 35 Ko à 20 Ko :
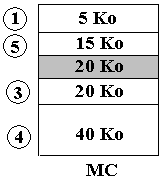
La taille du bloc d'espace libre diminue.
Continuons l'exécution du processus P en supposant que ce soit maintenant le segment n°1 qui devienne inutile :
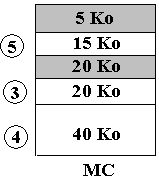
Il y a maintenant séparation de l'espace libre (fragmentation) en deux blocs, l'un de 5 Ko de mémoire contiguë, l'autre de 20 Ko de mémoire contiguë, soit un total de 25 Ko de mémoire libre. Il est toutefois impossible au système de charger le segment n°6 qui occupe 23 Ko de mémoire, car il lui faut 23 Ko de mémoire contiguë. Les système doit alors procéder à une réorganisation de la mémoire libre afin d'utiliser "au mieux" ces 25 Ko de mémoire libre.
Compactage
Dans le cas de la gestion de la MC par segmentation pure, un algorithme de compactage est lancé dès que cela s'avère nécessaire afin de ramasser ces fragments de mémoire libre éparpillés et de les regrouper dans un grand bloc de mémoire libre (on dénomme aussi cette opération de compactage sous le vocable de ramasse miettes ou garbage collector)
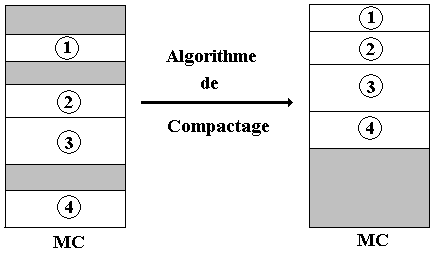
La figure précédente montre à gauche, une mémoire fragmentée, et à droite la même mémoire une fois compactée.
Adresse virtuelle - adresse physique
Nous avons parlé d'adresse logique d'une donnée par exemple, comment le système de gestion d'une mémoire segmentée retrouve-t-il l'adresse physique associée : l'OS dispose pour cela d'une table décrivant la "carte" mémoire de la MC.
Cette table est dénommée table des segments, elle contient une entrée par segment actif et présent dans la MC.
Une entrée de la table des segments comporte le numéro du segment, l'adresse physique du segment dans la MC et la taille du segment.

Liaison entre Table des segments et le segment lui-même en MC :
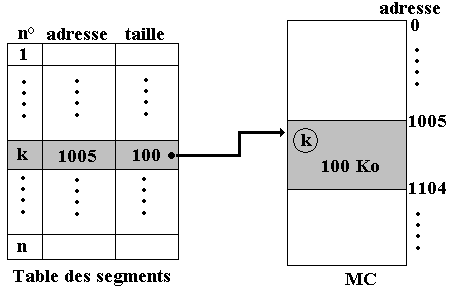
Lorsque le système de gestion mémoire rencontre une adresse virtuelle de cellule (n° segment, Déplacement), il va chercher dans la table l'entrée associée au numéro de segment, récupère dans cette entrée l'adresse de départ en MC du segment et y ajoute le déplacement de l'adresse virtuelle et obtient ainsi l'adresse physique de la cellule.
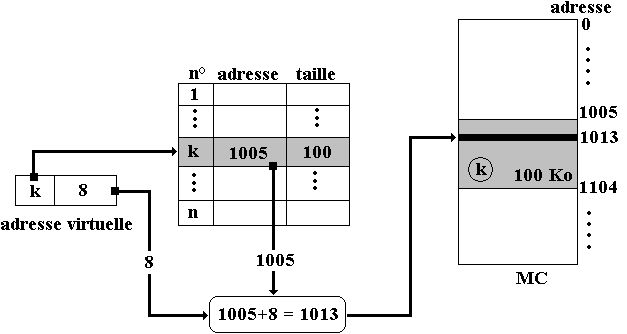
En reprenant l'exemple de la figure précédente, supposons que nous présentons l'adresse virtuelle ( k , 8 ). Il s'agit de référencer la cellule d'adresse 8 à l'intérieur du segment numéro k. Comme le segment n°k est physiquement implanté en MC à partir de l'adresse 1005, la cellule cherchée dans le segment se trouve donc à l'adresse physique 1005+8 = 1013.
La figure ci-après illustre le mécanisme du passage d'une adresse virtuelle vers l' adresse physique à travers la table des segments sur l'exemple ( k , 8 ).
La segmentation mémoire n'est pas la seule méthode utilisée pour gérer de la mémoire virtuelle, nous proposons une autre technique de gestion de la mémoire virtuelle très employée : la pagination mémoire. Les OS actuels employant un mélange de ces deux techniques, le lecteur se doit donc d'être au fait des mécanismes de base de chaque technique.
3.2 Mémoire virtuelle et pagination
Comme dans la segmentation mémoire, la pagination est une technique visant à partitionner la mémoire centrale en blocs (nommés ici cadres de pages) de taille fixée contrairement aux segments de taille variable.
Lors de l'exécution de plusieurs processus découpés chacun en plusieurs pages nommées pages virtuelles. On parle alors de mémoire virtuelle paginée. Le nombre total de mémoire utilisée par les pages virtuelles de tous les processus, excède généralement le nombre de cadres de pages disponibles dans la MC.
Le système de gestion de la mémoire virtuelle paginée est chargé de gérer l'allocation et la désallocation des pages dans les cadres de pages.
- La MC est divisée en un nombre de cadres de pages fixé par le système (généralement la taille d'un cadre de page est une puissance de 2 inférieure ou égale à 64 Ko).
- La taille d'une page virtuelle est exactement la même que celle d'un cadre de page.
- Comme le nombre de pages virtuelles est plus grand que le nombre de cadres de pages on dit aussi que l'espace d'adressage virtuel est plus grand que l'espace d'adressage physique. Seul un certain nombre de pages virtuelles sont présentes en MC à un instant fixé.
A l'instar de la segmentation, l'adresse virtuelle (logique) d'une donnée dans une page virtuelle, est composée par le numéro d'une page virtuelle et le déplacement dans cette page. L'adresse virtuelle est transformée en une adresse physique réelle en MC, par une entité se nommant la MMU (Memory Management Unit) assistée d'une table des pages semblable à la table des segments.
La table des pages virtuelles
Nous avons vu dans le cas de la segmentation que la table des segments était plutôt une liste (ou table dynamique) ne contenant que les segments présent en MC, le numéro du segment étant contenu dans l'entrée. La table des pages virtuelles quant à elle, est un vrai tableau indicé sur les numéros de pages. Le numéro d'une page est l'indice dans la table des pages, d'une cellule contenant les informations permettant d'effectuer la conversion d'une adresse virtuelle en une adresse physique.
Comme la table des pages doit référencer toutes les pages virtuelles et que seulement quelques unes d'entre elles sont physiquement présentes en MC, chaque page virtuelle se voit attribuer un drapeau de présence (représenté par un bit, la valeur 0 indique que la table est actuellement absente, la valeur 1 de ce bit indique qu'elle est actuellement présente en MC).
Schéma simplifié d'une gestion de MC paginée (page d'une taille de 64Ko) illustrant le même exemple que pour la segmentation, soit accès à une donnée d'adresse 8 dans la page de rang k, le cadre de page en MC ayant pour adresse 1005, la page étant présente en MC :
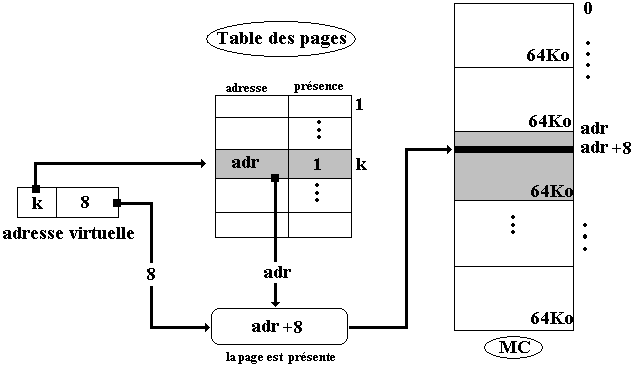
Lorsque la même demande d'accès à une donnée d'une page a lieu sur une page qui n'est pas présente en MC, la MMU se doit de la charger en MC pour poursuivre les opérations.
Défaut de page
Nous dirons qu'il y a défaut de page lorsque le processeur envoie une adresse virtuelle localisée dans une page virtuelle dont le bit de présence indique que cette page est absente de la mémoire centrale. Dans cette éventualité, le système doit interrompre le processus en cours d'exécution, il doit ensuite lancer une opération d'entrée-sortie dont l'objectif est de rechercher et trouver un cadre de page libre disponible dans la MC dans lequel il pourra mettre la page virtuelle qui était absente, enfin il mettra à jour dans la table des pages le bit de présence de cette page et l'adresse de son cadre de page.
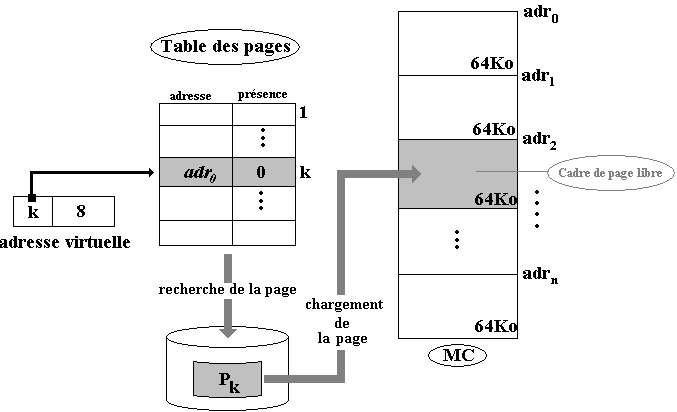
La figure précédente illustre un défaut de page d'une page Pk qui avait été anciennement chargée dans le cadre d'adresse adr0, mais qui est actuellement absente. La MMU recherche cette page par exemple sur le disque, recherche un cadre de page libre (ici le bloc d'adresse adr2 est libre) puis charge la page dans le cadre de page et l'on se retrouve ramené au cas d'une page présente en MC :
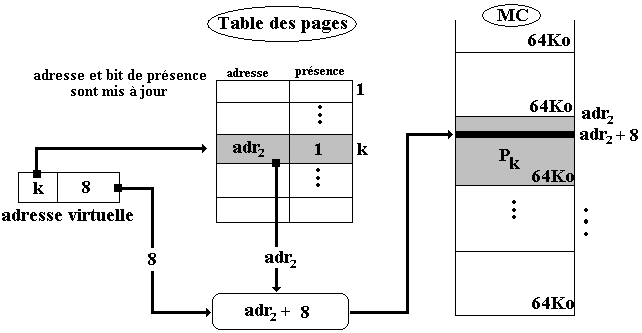
En fait, lorsqu'un défaut de page se produit tous les cadres de pages contiennent des pages qui sont marquées présentes en MC, il faut donc en sacrifier une pour pouvoir caser la nouvelle page demandée. Il est tout à fait possible de choisir aléatoirement un cadre de page, de le sauvegarder sur disque et de l'écraser en MC par le contenu de la nouvelle page.
Cette attitude qui consiste à faire systématiquement avant tout chargement d'une nouvelle page une sauvegarde de la page que l'on va écraser, n'est pas optimisée car si la page que l'on sauvegarde est souvent utilisée elle pénalisera plus les performances de l'OS (car il faudra que le système recharge souvent) qu'une page qui est très peu utilisée (qu'on ne rechargera pas souvent).
Cette recherche d'un "bon" bloc à libérer en MC lors d'un défaut de page est effectuée selon plusieurs algorithmes appelés algorithmes de remplacement. Nous donnons une liste des principaux noms d'algorithmes utilisables en cas de défaut de page. Tous ces algorithmes diffèrent par la méthode qu'ils emploient pour choisir la page de remplacement (bloc libre) selon sa fréquence d'utilisation ou bien selon le temps écoulé depuis sa dernière utilisation :
NRU ( Not Recently Use )
LRU ( Last Recently Use )
LFU ( Last Frequently Use )
MFU ( Most Frequently Use )
NFU ( Not Frequently Use )
FIFO ( Fist In First Out )
L'algorithme LRU semble être le plus performant dans le maximum de cas et il est celui qui est le plus utilisé. Cet algorithme nécessite une gestion supplémentaire des pages libres en MC selon une liste d'attente : la page la plus récemment utilisée est la première de la liste, elle est suivie par la deuxième page la plus récemment utilisée et ainsi de suite jusqu'au dernier élément de la liste qui est la page la moins récemment utilisée.
Le fondement pratique de cet algorithme se trouve dans le fait qu'une page qui vient d'être utilisée a de bonne chance d'être réutilisée par la suite très rapidement.
Dans les OS, les concepteurs élaborent des variantes personnalisées de cet algorithme améliorant tel ou tel aspect.
Les micro-ordinateurs apparus dans le grand public dès 1978 avec le Pet de Commodore, l’Apple et l’IBM-PC, ont répété en accéléré les différentes phases d’évolution des générations d’ordinateurs. Les OS des micro-ordinateurs ont suivi la même démarche et sont partis de systèmes de monoprogrammation comme MS-DOS et MacOS pour évoluer en systèmes multi-tâches (version affaiblie de la multiprogrammation) avec OS/2 , windows et Linux.
De nos jours un OS de micro-ordinateur doit nécessairement adopter des normes de convivialité dans la communication homme-machine sous peine d’être rejeté par le grand public. Là, gît à notre sens, un des seuls intérêts de l’impact puissant du marché sur l’informatique. La pression des masses de consommateurs a fait sortir l’informatique des milieux d’initiés, et s’il n’y avait pas cette pression, les OS seraient encore accessibles uniquement par des langages de commandes textuels dont les initiés raffolent (la compréhension d’un symbolisme abstrus dénotant pour certains la marque d’une supériorité toute illusoire et assez insignifiante). Notons aussi que la réticence au changement, la résistance à la nouveauté et la force de l’habitude sont des caractéristiques humaines qui n’ont pas favorisé le développement des interfaces de communication. La communication conviviale des années 90-2000 réside essentiellement dans des notions inventées dans les années 70-80 à Xerox PARC (Palo Alto Research Center of Xerox), comme la souris, les fenêtres, les menus déroulants, les icônes, et que la firme Apple a commercialisé la première dans l’OS du MacIntosh dès 1984. Windows de Microsoft et OS/2 d’IBM se sont d’ailleurs ralliés à cette ergonomie.
Outre le système Mac OS (un Unix-like version OS X) du MacIntosh d'Apple qui ne représente qu'une petite part du marché des OS vendus sur micro-ordinateurs ( environ 3% du marché), deux OS se partagent en proportion très inégale ce même marché Windows de Microsoft ( environ 90% du marché) et Linux OS open source du monde libre ( moins de 10% du marché), Linux représentant presque 50% des OS installés pour les serveurs Web. Le BeOs est un autre système Unix-like développé pour micro-ordinateur lui aussi fondé sur des logiciels GNU mais il est officiellement payant (le prix est modeste et équivalent aux distributions de Linux).
4.1 Le système d’exploitation du monde libre Linux
A.Tannenbaum écrit en 1987 pour ses étudiants, un système d'exploitation pédagogique baptisé MINIX fondé sur le système UNIX : c'est a naissance d'un système d'exploitation fondé sur Unix sans droit de licence. Linus Thorvalds reprend l'OS Minix et en 1994, la première version opérationnelle et stable d'un nouveau système est accessible gratuitement sous le nom de LINUX.
UNIX est un OS de multi-programmation commercial fondé lui-même sur les concepts du système MULTICS et construit par des chercheurs du MIT et des laboratoires Bell. Il s'agissait d'une version allégée de MULTICS qui a fonctionné durant les années 1960-1970 sur de très gros ordinateurs. Les centres de calculs inter-universitaires français de cette décennie fonctionnaient sous MULTICS. L'OS Unix a été largement implanté et distribué sur les mini-ordinateurs PDP-11 de la société DEC et sur les VAX successeurs des PDP-11 de la même société.
Unix se voulait un système d'exploitation portable et universel, malheureusement des versions différentes et incompatibles entre elles ont été développées et cet état de fait perdure encore de nos jours. Nous trouvons actuellement des Unix dérivés de BSD (de l'université de Berkeley) le plus connu étant FreeBSD et des Unix dérivés du System V (de la société ATT).
Points forts de Linux
- Linux n'étant pas soumis aux contraintes commerciales, reste unique puisque les enrichissements qui lui sont apportés ne peuvent être propriétaires.
- Linux contient tout ce qu'une version commerciale d'Unix propose, sauf la maintenance système qui n'est pas garantie.
- Linux rassemble et intègre des fonctionnalités présentes dans les deux Unix BSD et System V.
- Vous pouvez modifier Linux et le revendre, mais vous devez obligatoirement fournir toutes les sources à l'acheteur.
- Linux supporte le multithreading et la pagination mémoire.
Points faibles de Linux
- Utiliser le système Linux, même avec une interface comme KDE ou Gnome demande une compétence particulière à l'utilisateur, car Linux reste encore orienté développeur plutôt qu'utilisateur final.
- Plusieurs distributions de Linux coexistent. Une distribution comporte un noyau commun, portable et standard de Linux accompagné de diverses interfaces, de programmes et d'outils systèmes complémentaires et de logiciels d'installations, nous citons quelques distributions les plus connues : Mandrake, Red Hat, Debian, Suse, Caldera,… Cette diversité donne au final un éventail de "facilités" qui semble être trop large parce que différentes entre elles et pouvant dérouter l'utilisateur non informaticien.
Linux essaie de concurrencer le système Windows sur PC, le match est encore inégal en nombre de logiciels installés fonctionnant sous cet OS, malgré un important battage médiatique effectué autour de ce système dans la fin des années 90 et les rumeurs récurrentes de la disparition de Windows voir même de la société Microsoft.
4.2 Le système d’exploitation Windows de MicrosoftLe premier système d'exploitation de PC (Personnal Computer) conçu par la société Microsoft dans le début des années 1980 se nomme MS-DOS ( système de mono-programmation) qui a évolué en véritable système de multi-programmation (avec processus, mémoire virtuelle, multi-tâches préemptif…etc) à partir de Windows 95, puis Windows 98, Me. La première version de Windows non basée sur MS-DOS a pour nom de code Windows NT au début des années 1990, depuis Windows 2000 qui est une amélioration de Windows NT, les successeurs comme Windows 2003, Xp et longhorn sont des systèmes d'exploitation à part entière, qui possèdent les mêmes fonctionnalités fondamentales qu'Unix et donc Linux.
Une grande différence entre Linux et Windows se situe dans la manière de gérer l'interface utilisateur (partie essentielle pour l'utilisateur final qui n'est pas un administrateur système). Cette remarque peut expliquer l'écart important d'installation de ces deux systèmes sur les PC. En outre les démarches intellectuelles qui ont sous-tendu la construction de chacun de ces deux système sont inverses.
Linux
En effet, Linux est dérivé d'un système d'exploitation inventé pour les gros ordinateurs des années 70, système auquel il a été rajouté un programme utilisateur non privilégié appelé interface de communication (KDE, Motif, Gnome, …) de cette architecture découle le foisonnement d'interfaces différents déroutant l'utilisateur de base.
Windows
Windows à l'inverse, est parti d'un OS primitif et spécifique à un PC pour intégrer au cours du temps les fonctionnalités d'un OS de mainframe (gros ordinateur). L'interface de communication (le fenêtrage graphique) est intégré dans le cœur même du système. Le mode console (interface en ligne de commande genre MS-DOS ou ligne de commande Linux) est présent mais est très peu utilisé, les fonctionnalités de base du système étant assurées par des processus fenêtrés.
Les deux systèmes Linux et Windows fonctionnent sur les plates-formes basées sur les principaux micro-processeurs équipant les PC du marché (Intel majoritairement et AMD) aussi bien sur l'architecture 32 bits que sur l'architecture 64 bits toute récente.
Etant donné la remarquable croissance de l'innovation en technologie, les systèmes d'exploitation évoluent eux aussi afin d'adapter le PC aux différents outils inventés. Enfin, il y a bien plus d'utilisateurs non informaticiens qui achètent et utilisent des PC que d'informaticiens professionnels, ce qui implique une transparence et une convivialité obligatoire dans les communications homme-machine. Un OS idéal pour PC grand public doit convenir aussi bien au professionnel qu'à l'utilisateur final, pour l'instant Windows l'emporte très largement sur Linux, mais rien n'est dit, le consommateur restera l'arbitre.
Nous avons abordé ici des fonctionnalités importantes d'un système d'exploitation, nous avons indiqué qu'un OS assurait d'autres grandes fonctions que nous n'avons pas abordées, comme la gestion des entrées-sorties, l'interception des interruptions, la gestion des données sur des périphériques comme les disques durs dévolue au module de gestion des fichier de l'OS. Ici aussi le lecteur intéressé par l'approfondissement du domaine des systèmes d'exploitation peut se référer à la bibliographie, en particulier un ouvrage de 1000 pages sur les OS par le père de MINIX A.Tannebaum.